Calibration is not just about building a model — it’s also about understanding how that model will be used in practice. This post revisits a common measurement scenario: a transducer is calibrated using polynomial regression, and then the challenge of inverse prediction is faced — estimating the input that produced an observed output. Along the way, I examine the conceptual pitfalls of model inversion, and reflect on the practical consequences of noise, nonlinearity, and extrapolation in real deployment settings via a Monte Carlo simulation.
Author
Angelo Maria Sabatini
Published
May 29, 2025
Calibrating a transducer means establishing a functional relationship between a physical input (e.g., pressure, temperature, force) and a measured output. In many real-world applications, however, the actual objective lies elsewhere: once the system is calibrated, the focus shifts to model inversion. Given an observed output, the task is to determine which input value could plausibly have produced it. This is precisely the challenge faced during deployment, when the transducer is integrated into an operational system.
This post explores — through a simple but realistic example — the conceptual limits of direct model inversion in regression. The discussion also includes a brief note on orthogonal regression and introduces a Monte Carlo simulation strategy for addressing inverse prediction.
Simulating a calibration scenario
A simplified yet technically plausible calibration scenario is considered. The system under calibration is a nonlinear transducer — for instance, a sensor whose output voltage varies smoothly with a physical input quantity such as pressure or displacement. The underlying (noiseless) response function is assumed to be injective, meaning that each output corresponds to exactly one input value. In functional terms, the response curve is monotonic, ensuring that inversion remains well-defined in the absence of noise.
The true input–output relationship is assumed to follow a smooth nonlinear curve, here modeled as a fourth-degree polynomial (truth model). Measurement noise is introduced by adding zero-mean Gaussian noise with standard deviation \(\sigma\) to the target outputs.
The R code below simulates 25 calibration data points from the reference model. A distinction is drawn between the transducer’s full operating range, \([0,12]\), and the actual calibration interval, \([1,11]\) — henceforth referred to as the measurement interval. This setup reflects common practice, where calibration is limited to a central portion of the device’s range. Within this interval, an operating point \(x^*=3.5\) is selected, corresponding to a target output \(y^*=11\). All variables are expressed in arbitrary units.
Simulate the calibration dataset
library(tidyverse)set.seed(123)x_full <-seq(0, 12, length.out =25)# Coefficients for a strictly increasing polynomial on [0, 10]beta <-c(0.681125, 1.2, 0.3, 0.05, 0.002)# Define the operating point ...x_star <-3.5# ... the corresponding target outputy_star <-11# Truth model functionf_true <-function(x) { beta[1] + beta[2]*x + beta[3]*x^2+ beta[4]*x^3+ beta[5]*x^4}# True outputsy_true <-f_true(x_full)sigma <-1y <- y_true +rnorm(length(x_full), mean =0, sd = sigma)# Build full datasetdf_full <-data.frame(x = x_full, y = y, y_true = y_true)# Subset for calibration: (1, 11)df_calib <-subset(df_full, x >1& x <11)
Cautionary note: The noise added to the simulated outputs assumes constant standard deviation and Gaussian distribution — a deliberate simplification. In reality, calibration is often performed under carefully controlled laboratory conditions, which minimize thermal drift, power supply variations, and other environmental effects.
Once deployed, however, the transducer is left to “breathe” — it operates in a dynamic environment, subject to factors that were effectively considered constant during calibration. As a result, the actual variability in output readings is typically greater than what the calibration model suggests.
Moreover, it is not uncommon for the noise standard deviation to depend on the input value itself — for instance, in thermocouples or strain gauge sensors, measurement variability often increases with temperature or applied force due to physical nonlinearities and sensitivity drift and/or drop.
Fitting the calibration model
Calibration is performed by fitting a polynomial regression model to the observed data — restricted to the measurement interval, as would typically be the case in practice to avoid excessive extrapolation at the boundaries. A fourth-degree polynomial is fitted using least squares, which coincides with the true data-generating mechanism adopted in the simulation (though in real applications, such knowledge would not be available).
Fit a 4th-degree polynomial model
# Fit the calibration model only within (1, 11)model_poly4 <-lm(y ~poly(x, 4), data = df_calib)# Predict over the full domain for visualizationdf_full$y_pred <-predict(model_poly4, newdata = df_full)
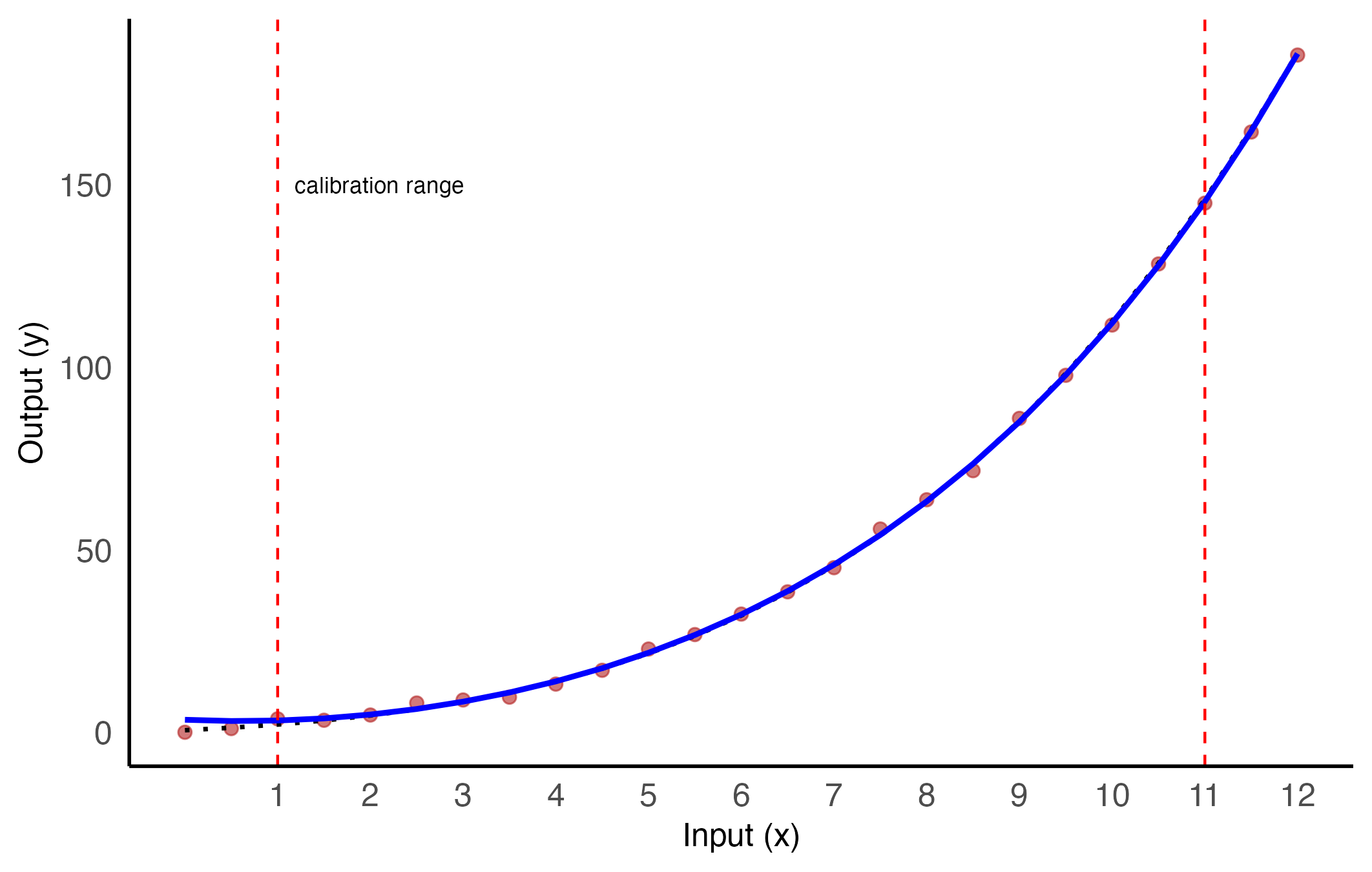
To better understand the validity range of the model, we plot the full dataset along with the fitted curve, highlighting the measurement interval.
To assess the validity domain of the fitted model, the entire dataset is visualized alongside the estimated regression curve Figure 1. The measurement interval is explicitly marked, highlighting the region where data were actually used for model fitting. Outside this interval, the model operates in extrapolation mode, relying on limited or no information — a situation in which prediction accuracy and reliability can rapidly deteriorate.
Figure 1: The red points represent noisy measurements, the dotted black line indicates the true model, and the solid blue line shows the fitted polynomial curve. The dashed vertical lines mark the boundaries of the measurement interval.
From direct prediction to inversion
Now suppose the calibrated system is to be used in the field. For a new observed target output \(y^*\), the goal is to estimate the corresponding input \(x\) under the fitted model. This task is known as inverse prediction. A common misunderstanding is to simply reverse the roles of input and output and fit a new regression model of the form \(x \sim y\). This “reversed regression” approach, however, lacks a solid statistical foundation and yields incorrect uncertainty estimates — especially when measurement noise affects the output, not the input.
In most calibration settings, the values of the input variable are assumed to be known with negligible uncertainty, while the output is subject to measurement noise. This asymmetry is foundational: classical regression assumes uncertainty in the response, not in the predictor. Swapping their roles invalidates that assumption and leads to biased estimates. The underlying statistical inconsistency is further discussed below in the context of orthogonal regression.
Instead, the correct formulation requires solving the equation
\[
\hat{y}(x) = y^*
\]
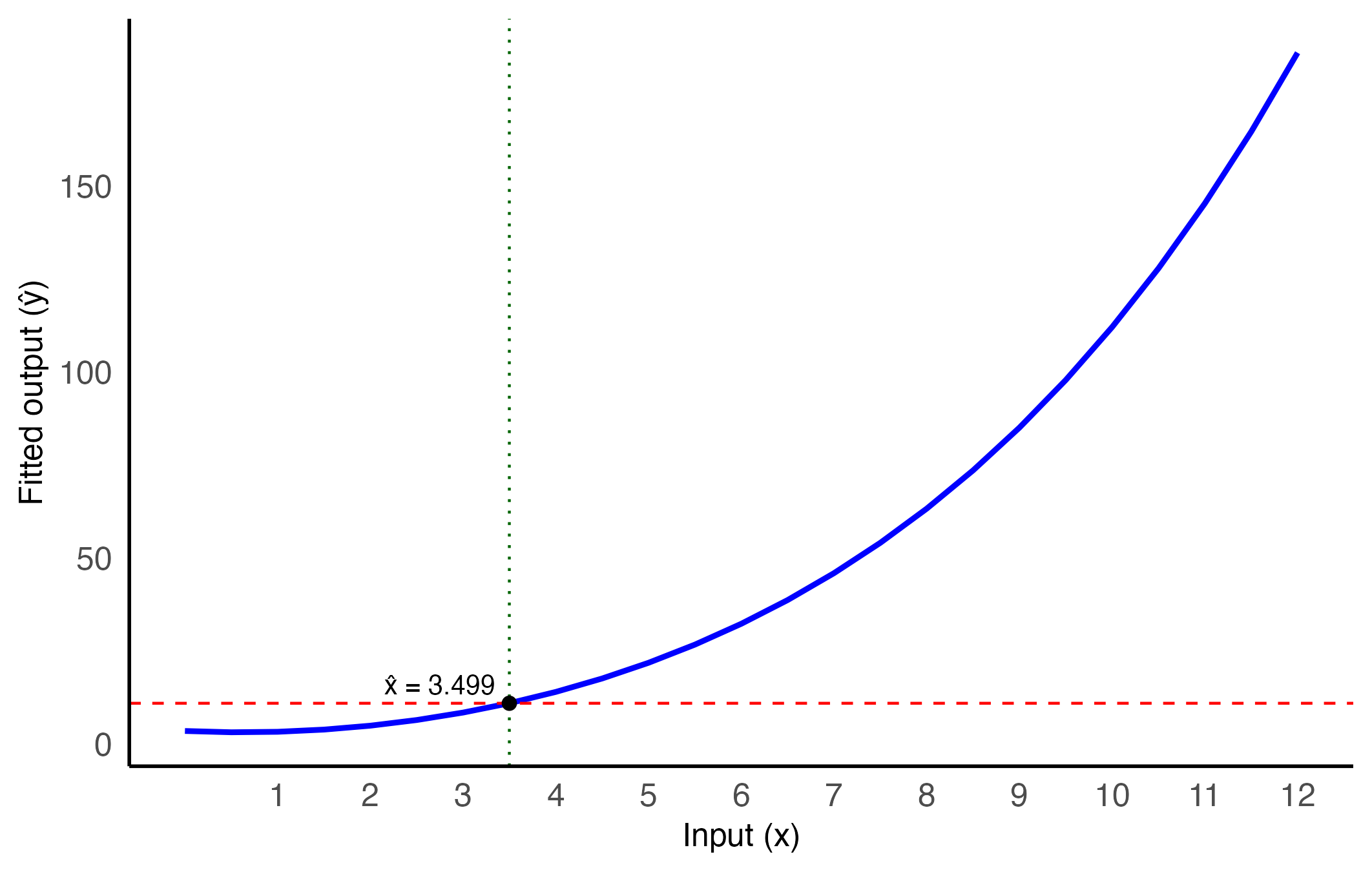
i.e., finding the value of \(x\) for which the predicted output equals the observed measurement. In general, this equation cannot be solved in closed form for a polynomial of degree greater than two, unless specific simplifying conditions apply. However, since the fitted polynomial is strictly increasing over the full input domain \([0, 12]\), the solution exists and is unique for any \(y^*\) in the measurement interval, where reliable inverse predictions can thus be expected.
The inversion can be carried out numerically — for example, using uniroot() in R, which implements the bisection method. This approach is robust and well-suited to continuous, monotonic functions like the fitted polynomial. Below, the inversion is performed for the chosen target output.
Invert the calibration model
# Define the target outputy_star <-11# Define the prediction function from the modelpredict_poly <-function(x) {predict(model_poly4, newdata =data.frame(x = x))}# Define the function to solve: f(x) = y_pred(x) - y_starf_inversion <-function(x) predict_poly(x) - y_star# Solve numerically in the interval [1, 11] (calibration zone)x_hat <-uniroot(f_inversion, lower =1, upper =11)$root
An target output of 11 corresponds to an estimated input of 3.499, based on the fitted calibration model.
Figure 2: The fitted regression curve (blue line) is inverted numerically for the target output \(y^* = 11\) (horizontal red dashed line), yielding the corresponding estimate \(\hat{x}\) of the operating point (vertical dotted line). The point \((\hat{x}, y^*)\) is marked on the curve to illustrate the solution.
This kind of inverse prediction relies entirely on the deterministic structure of the fitted model and does not account for uncertainty. In the next section, a Monte Carlo approach will be introduced to estimate the distribution of plausible inputs given an observed output.
Before proceeding, it is useful to reflect on the geometry of the problem — in particular, on the fact that ordinary least-squares regression minimizes the sum of squared vertical distances from the data points to the fitted curve. This choice is justified when the input variable is regarded as fixed and known without error, and all uncertainty is attributed to the output. When this assumption no longer holds — as is often the case in inverse usage — minimizing vertical deviations may no longer be the most appropriate strategy.
A geometric note: vertical vs orthogonal residuals
In classical regression, the output variable \(y\) is modeled as random, while treating the input \(x\) as fixed or measured without error — or equivalently, as a random variable with zero standard deviation. This modeling choice is what justifies minimizing the vertical distance between the observed \(y\) values and the fitted curve \(\hat{y}(x)\) in least-squares estimation.
However, when using the model in reverse — i.e., to estimate \(x\) given \(y\) — this assumption becomes questionable. In real-world settings, the input itself is subject to measurement uncertainty, or the roles of input and output may conceptually reverse (e.g., in calibration vs deployment).
This motivates the idea of orthogonal regression, or total least squares, where the residuals are measured perpendicularly to the curve, taking into account errors in both variables.
Although not implemented here, orthogonal regression serves as an important conceptual reminder: the least-squares fit is geometrically asymmetric. Direct prediction (forward use) is naturally supported; inverse prediction must be handled with care, especially in nonlinear settings like the one examined here.
Orthogonal regression in practice
A practical method for regression with errors in both x and y is Deming regression, which minimizes the sum of squared orthogonal distances to the fitted line, assuming a known error variance ratio.
While classical regression assumes the input x is known precisely — or has negligible variance — this is often not the case in calibration tasks, particularly when inputs are indirectly observed or reversed during deployment.
Deming regression has two key limitations here:
It applies only to linear models — not to polynomials like the one used above;
It requires the specification of the error variance ratio between \(x\) and \(y\). In practice, this ratio must be inferred from physical knowledge of the system, including the intrinsic noise of the transducer and the propagation of input uncertainty through the calibration curve.
While orthogonal regression becomes numerically complex in nonlinear settings, the next section takes a different route — not to improve the regression fit, but to explore how output noise affects the inference of input values. The goal is to simulate, under known conditions, how a calibrated system behaves when used in reverse.
Inverse prediction under different noise levels
This section illustrates a simulation-based strategy for inverse prediction. Given a target output, the goal is to characterize the distribution of input values \(x\) that could plausibly have generated it, under the assumption that the noise affecting the output is Gaussian and matches the standard deviation used during calibration.
The procedure is as follows:
Fix a target output \(y^*\);
Generate samples of random noise \(\varepsilon_i \sim \mathcal{N}(0, \sigma^2)\), using the known standard deviation;
For each sample, solve the perturbed equation:
\[
y(x_i)=y^*+\varepsilon_i
\]
using the truth model (i.e., the exact polynomial coefficients), to obtain a sample of input values consistent with the observed output.
This approach provides a probabilistic reconstruction of the likely inputs that could have produced a given output under a known model with output noise. It highlights how variability in the output propagates backward through the system, inducing uncertainty in the inferred inputs.
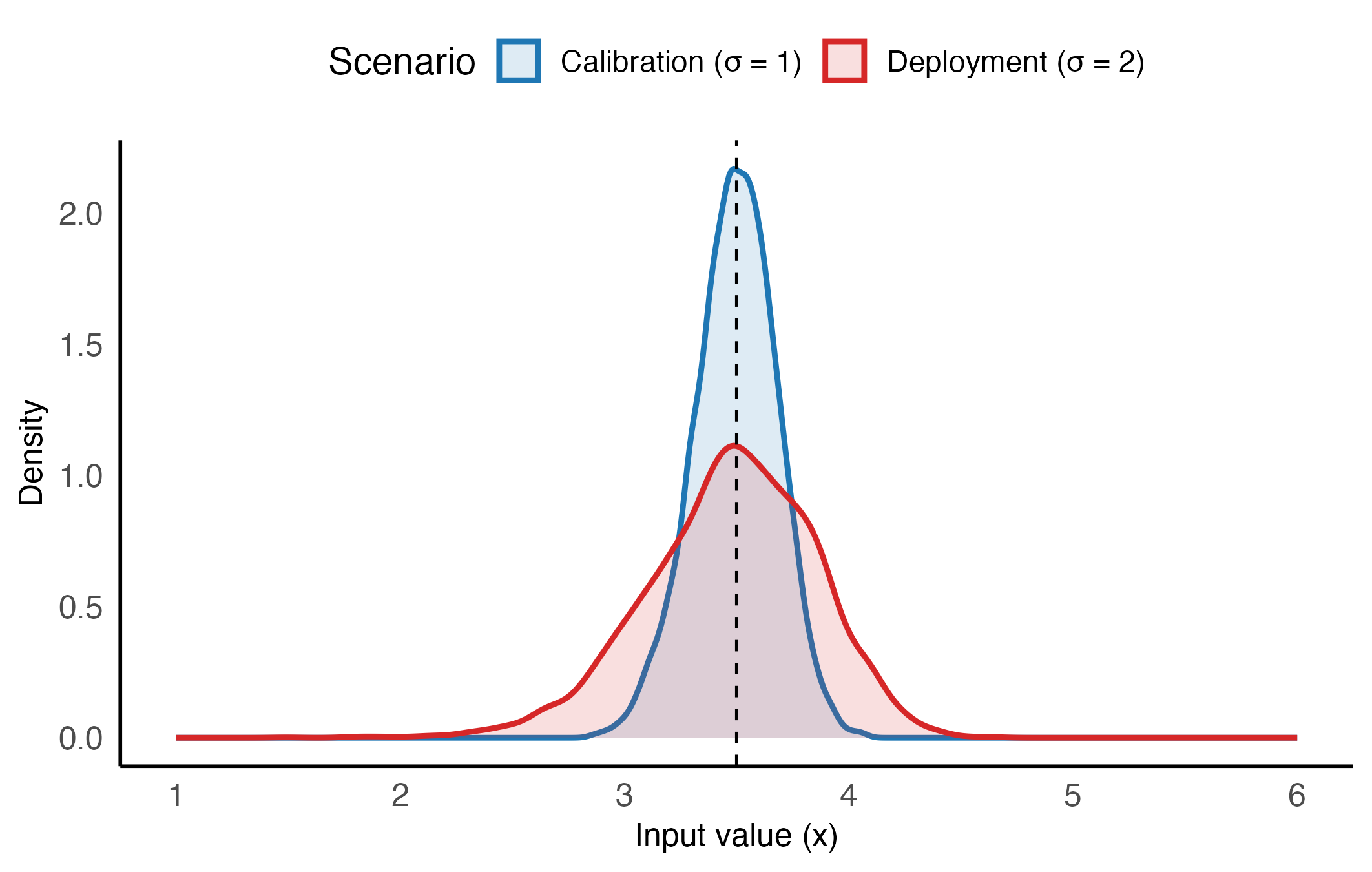
To illustrate how noise affects inverse estimation, two scenarios are compared. The first replicates the controlled conditions of the calibration process, where the noise level is low and well-characterized. The second represents a more realistic deployment setting, where the same transducer operates in a less stable environment, leading to larger variability in the output. By repeating the Monte Carlo simulation under both conditions, it becomes possible to observe how increased noise distorts the distribution of plausible input values — including shifts in bias, widening of confidence intervals, and an increase in failed inversion attempts due to extrapolation beyond the calibrated domain Figure 3.
Compare two noise scenarios for inverse prediction
Monte Carlo simulation under two noise scenarios. The table summarizes the distribution of input values consistent with the target output. The number of failed inversions (NA) indicates the samples falling outside the measurement interval.
Scenario
Monte Carlo mean (x̄)
Bias
95% CI (quantiles)
Failed inversions (NA)
σ = 1 (calibration)
3.494
-0.005
[3.112, 3.837]
0
σ = 2 (deployment)
3.474
-0.024
[2.663, 4.136]
0
Notation key
\(y^*\): target output to be inverted (deployment phase)
\(\hat{x}\): input estimate obtained by inverting the fitted model
\(x_i\): individual input values sampled via Monte Carlo simulation
\(\bar{x}\): empirical mean of the Monte Carlo input distribution
Bias: computed as \(\bar{x} - \hat{x}\)
Figure 3: Monte Carlo density estimates of input values consistent with the target output under two noise conditions. Blue: calibration scenario (\(\sigma = 1\)). Red: deployment scenario (\(\sigma = 2\)). The vertical dashed line marks \(\hat{x}\), the input estimate obtained by inverting the fitted model. As noise increases, the density skews leftward — a consequence of the fact that sensitivity (i.e., the slope of the calibration curve) tends to increase with input value. This results in asymmetric confidence intervals, with heavier tails toward lower \(x\) values.
This method illustrates how even a fixed output measurement may correspond to a range of plausible inputs. The spread of this distribution depends on the noise level, the local slope of the calibration curve near \(y^*\), and the model’s nonlinearity.
In linear settings, Monte Carlo inversion recovers the classical prediction interval for \(x^*\) derived from theory. In nonlinear cases, however, simulation becomes essential to reveal the actual shape and spread of the inverse uncertainty.
Key observations:
The peak of the simulated density typically does not align with \(\hat{x}\), the inverse prediction from the fitted model. This reflects a small bias introduced by the asymmetry of the transformation \(x \rightarrow y\), which distorts symmetric output noise into skewed input uncertainty.
Despite Gaussian noise on the output, the resulting distribution of plausible \(x\) values is not normal. Nonlinear calibration curves map symmetric errors into asymmetric input spreads, especially in regions with varying slope or curvature.
As noise increases, the inverse distribution becomes wider and increasingly left-skewed. This behavior is consistent with the increasing sensitivity of the model at higher \(x\) values and results in confidence intervals that shift and become asymmetric — as clearly shown in Figure 3. However, the use of numerical solvers like uniroot() comes with important caveats near the edges of the calibration domain. When the slope of the model becomes very small — as it often does at low input values — the inversion becomes ill-conditioned: small variations in output may correspond to large variations in input, or even result in multiple or no real-valued solutions. In such cases, the solver may return only one of several possible roots, typically the one closer to the lower boundary. This effect contributes to the asymmetric shape and heavy left tail of the inverse distribution shown in Figure 3, even when the output noise itself is symmetric.
A further complication arises from the fitted polynomial model used for inversion. While the interpolating polynomial approximates the calibration curve well over central regions, it tends to oscillate or flatten toward the boundaries, particularly in higher-order fits. These edge effects can amplify instability in the inverse prediction — both for numerical solvers and for lookup-table interpolation — unless the prediction range is appropriately restricted or the model complexity reduced.
A final word: this is the optimistic case
The Monte Carlo simulations shown so far illustrate a powerful approach to inverse prediction — but under conditions that are more optimistic than most real-world applications. In particular, the numerical solver was applied to the truth model, i.e., the same polynomial function used to generate the data. This means that, although noise was present in the output, the model structure was assumed to be perfectly known and invertible. In reality, due to computational constraints at deployment time or industrial protocols that can prevent real-time inversion via numerical methods, inverse prediction is rarely implemented via numerical solvers — more often, it relies on lookup tables derived from synthetic calibration curves.
A first step toward table-based inverse prediction
Lookup tables link input values to their expected outputs based on the fitted model, enabling fast and resource-efficient retrieval of approximate inverses during deployment.
The idea is simple:
Step 1: Generate a synthetic grid of input values over the calibration interval;
Step 2: Evaluate the fitted model on each input to obtain corresponding outputs;
Step 3: Store the resulting pairs \((x_j, \hat{y}_j)\) in a lookup table;
Step 4: At deployment, when an output \(y^*\) is observed, find the two closest values in the table and return the associated \(\hat{x}\) (possibly via linear interpolation between adjacent points). Of course, this step can work only if the table columns are strictly monotonic.
It is worth noting that the requirement of monotonicity is shared with the numerical solver: non-monotonic regions in the model may lead to multiple valid solutions or to failed inversions when the output falls outside the achievable range. However, the problem is often more acute with lookup tables. Unlike solvers, which can dynamically refine their search and isolate a valid root, lookup tables are constrained to a discrete grid of stored values — and interpolation may become unstable or misleading near flat or turning regions of the model.
This limitation highlights a trade-off between computational efficiency and robustness of inversion. It also suggests that, before deploying lookup-based inverse prediction, one should:
carefully inspect the fitted model for monotonicity;
possibly restrict the input range to regions where inversion is well-defined;
or simplify the model structure (e.g., reducing polynomial degree) to avoid non-monotonic behavior.
Test with a lookup table under deployment conditions
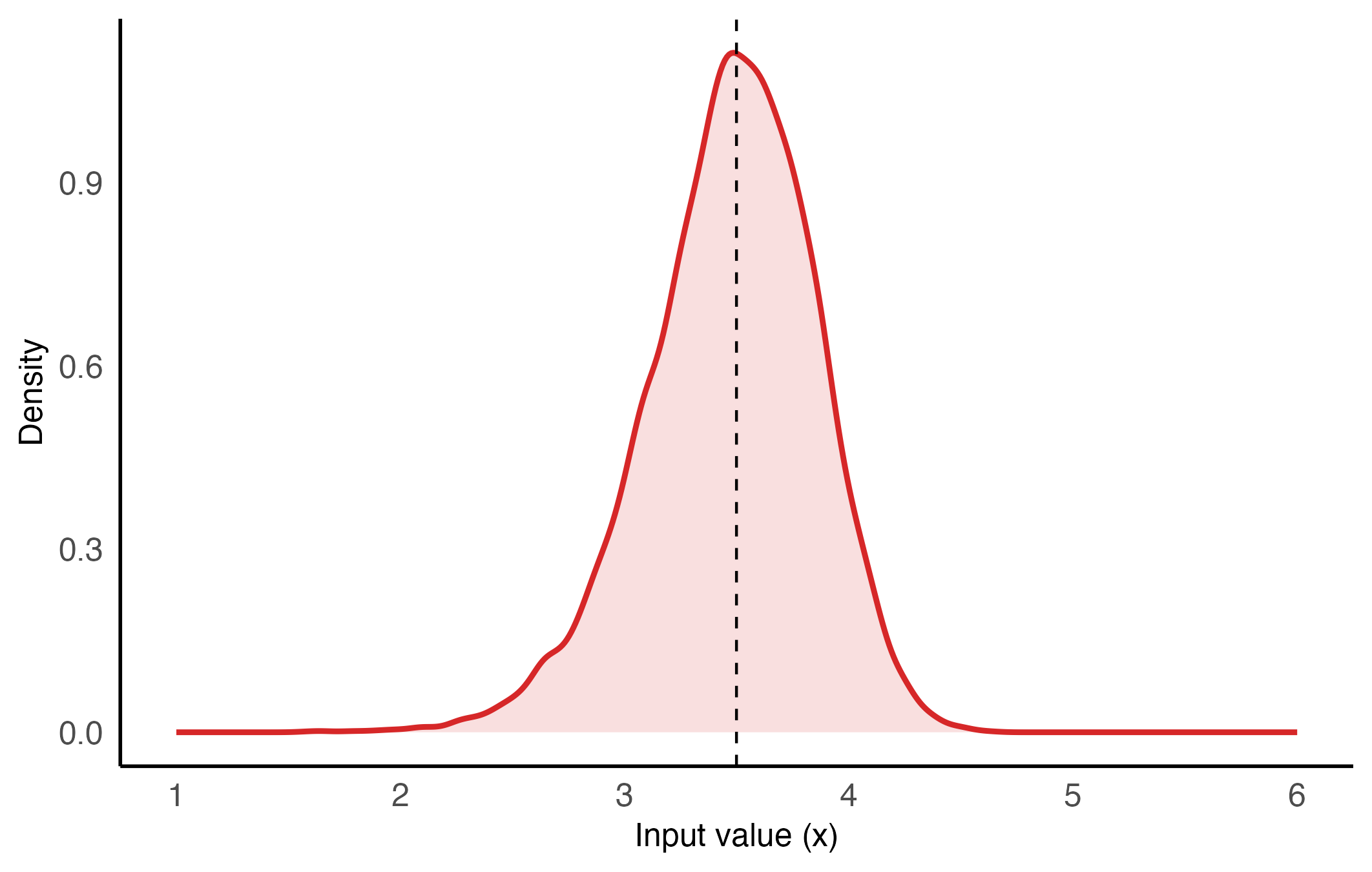
To evaluate inverse prediction under realistic deployment conditions, I simulate noisy output observations centered at the target output, with a standard deviation of \(\sigma=2\).
A lookup table is constructed from the fitted model, but only over a restricted interval where monotonicity has been both visually and numerically verified. This ensures that the inversion procedure remains well-defined and avoids regions where multiple or unstable solutions might occur.
Figure 4: Density of inverse input values obtained via a lookup table. Because of the good quality of the table in terms of monotonicity and range, the distribution closely resembles that obtained using the numerical solver in Figure 3. No inversion failures occurred in the Monte Carlo simulation. The 95% confidence interval is \([2.652, 4.126]\), with a Monte Carlo mean \(\bar{x} = 3.471\) and a bias of approximately \(-0.028\).
Conclusion and outlook
This post has explored the challenge of inverse prediction in static calibration, highlighting the often-overlooked asymmetry of uncertainty when working backward from output to input. Using both numerical solvers and lookup tables, I showed how Monte Carlo simulation can quantify the resulting variability — even in optimistic settings where the model is perfectly known and the only uncertainty comes from measurement noise.
Along the way, I emphasized that inverse prediction is more sensitive than forward prediction to model structure, output noise, and edge behavior. In particular, it should be remarked that:
confidence intervals become skewed and asymmetric as noise increases;
the numerical solver can fail silently near the domain boundaries;
lookup tables, while efficient and interpretable, require monotonicity and careful grid design.
I deliberately kept the noise levels moderate and the model structure well-behaved. This allowed us to isolate key phenomena without introducing unnecessary complications. But real-world problems are rarely so kind: noise and non-monotonicity are recurring nightmares — not just in calibration, but in data-driven projects, where transducers often serve as the gateway to the information we rely on.
The next post in this series will dive deeper into these complications. I’ll explore what happens when the true model structure is unknown or misestimated, when noise levels are high enough to push the inverse prediction outside the measurement interval, and when the forward function is non-monotonic. These “edge cases” pose significant risks — but also offer valuable opportunities to rethink how calibration is designed and implemented in practice.