Four identities of the coaxial cable: from magnetostatics to EMC
measurement
electromagnetism

When more data is not more information
stochastic modeling
signal processing
measurement
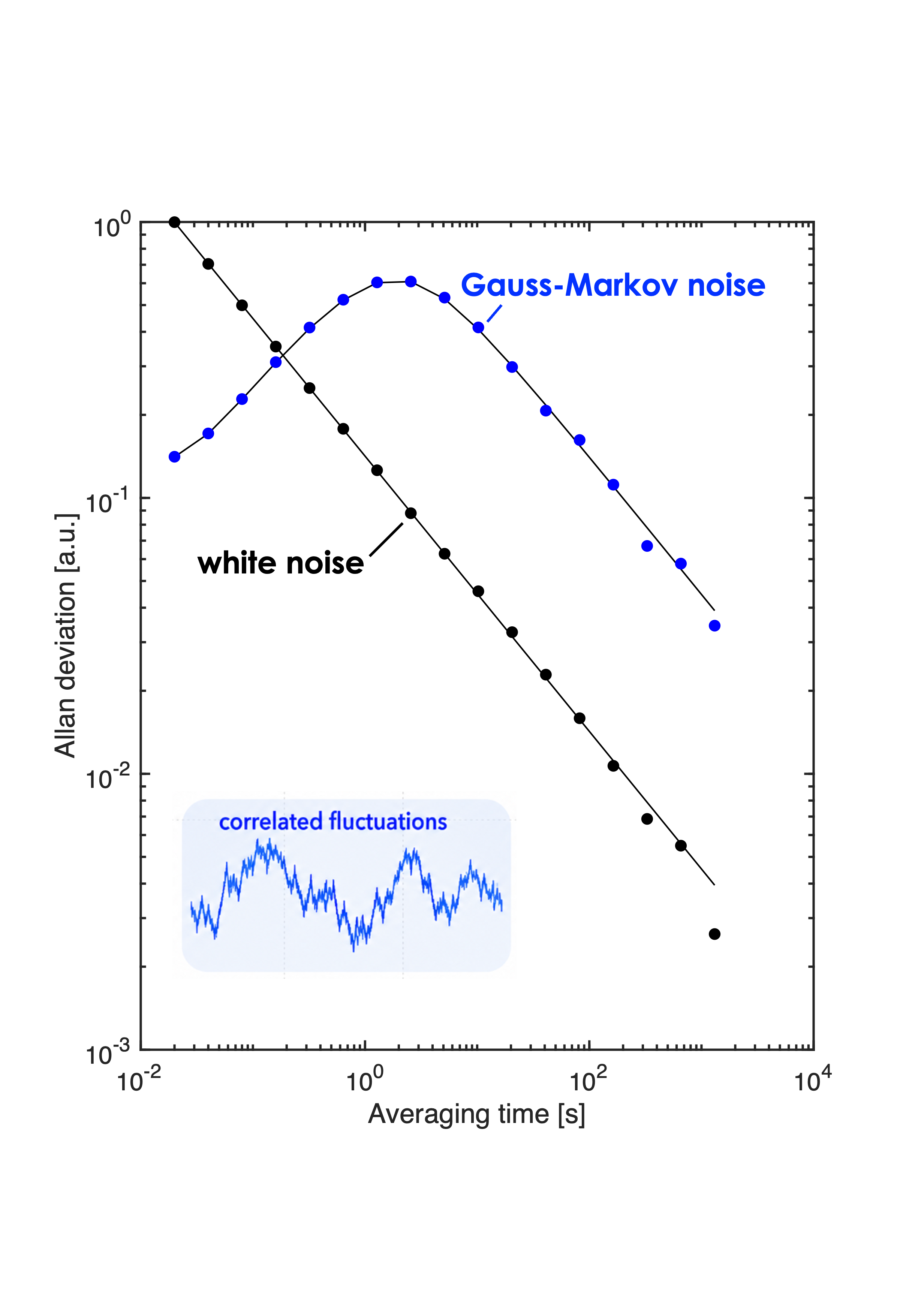
The hidden cost of correlated noise
stochastic modeling
signal processing
measurement

Is the sample mean a Kalman filter in disguise?
stochastic modeling
signal processing
measurement

What does a discrete-time noise generator really simulate?
stochastic modeling
signal processing
measurement
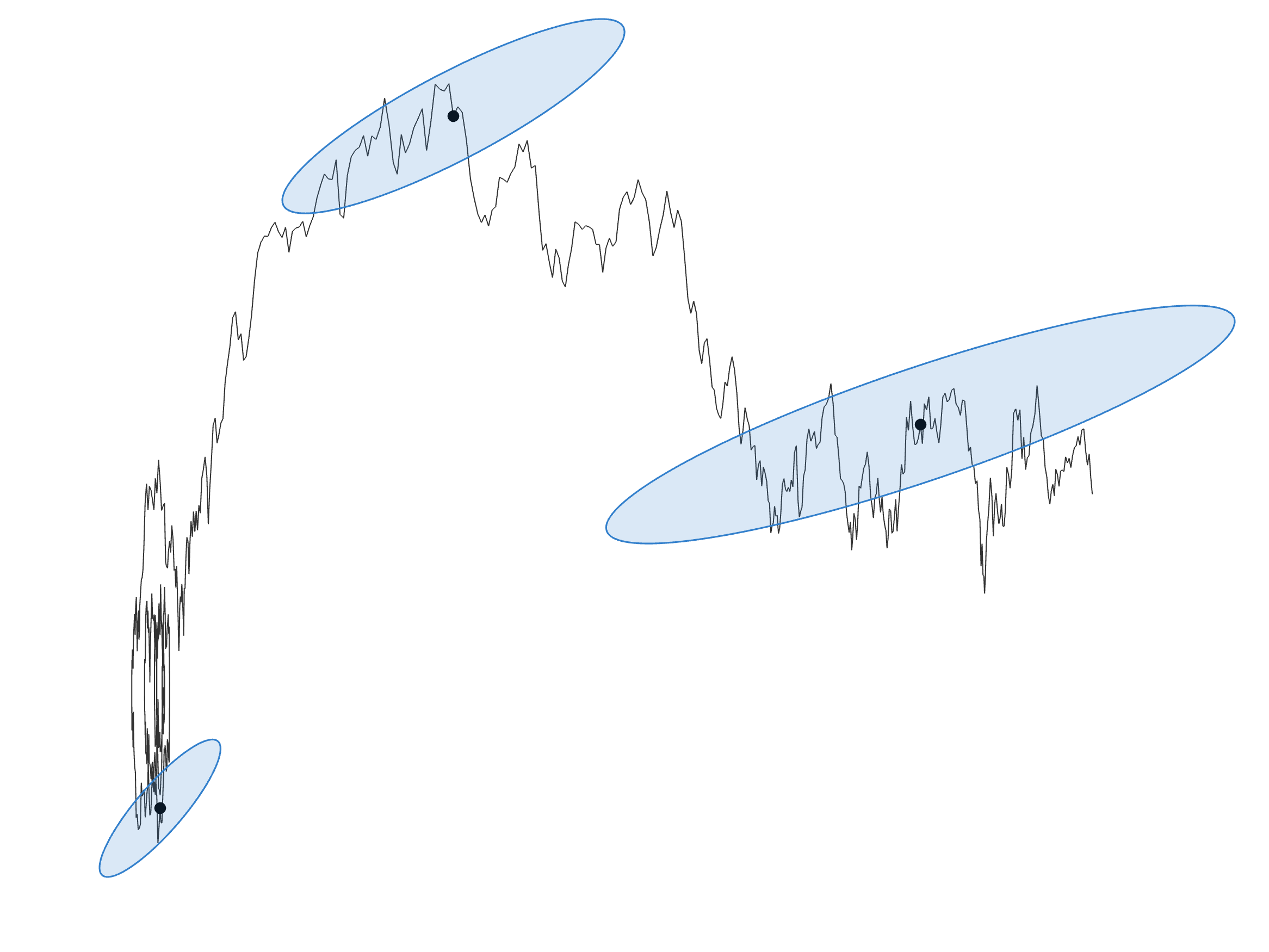
Discretizing motion under stochastic acceleration
stochastic modeling

PCA, MANOVA, and the geometry of multivariate comparison
multivariate statistics
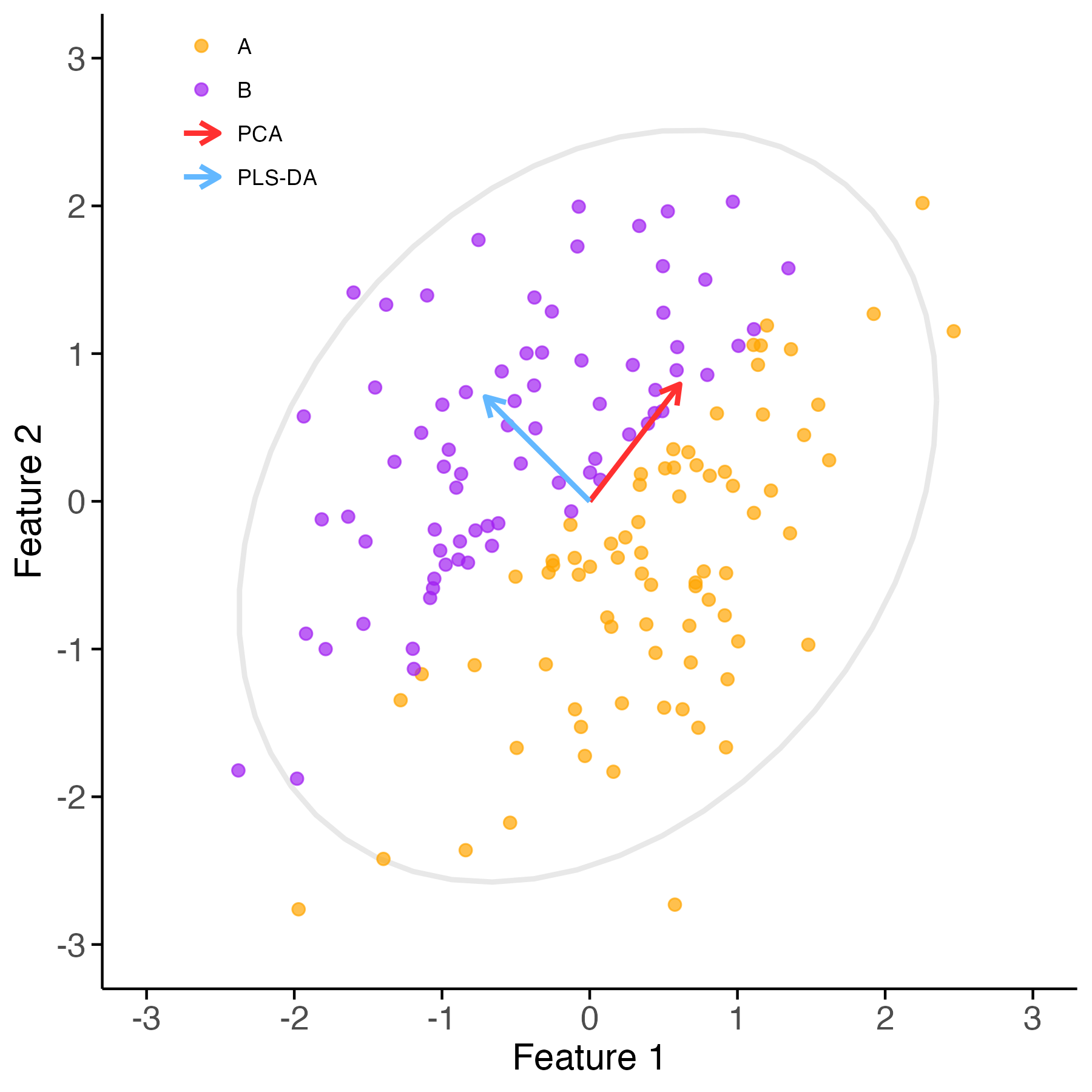
Partial Least-Squares Discriminant Analysis for text classification: A linear model that works
multivariate statistics
machine learning
text mining
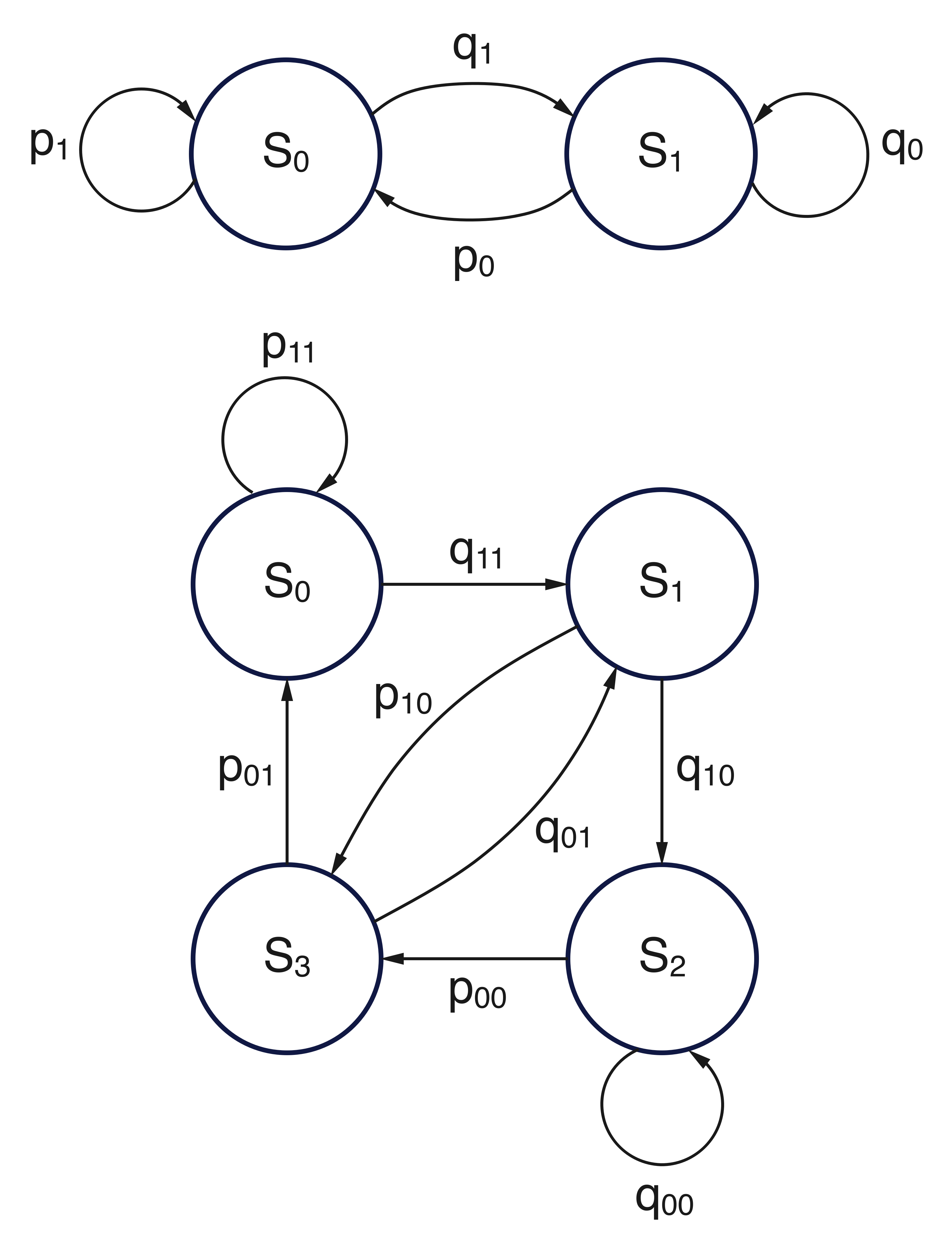
Why memory matters: A tale of two Markov chains
probability
statistics
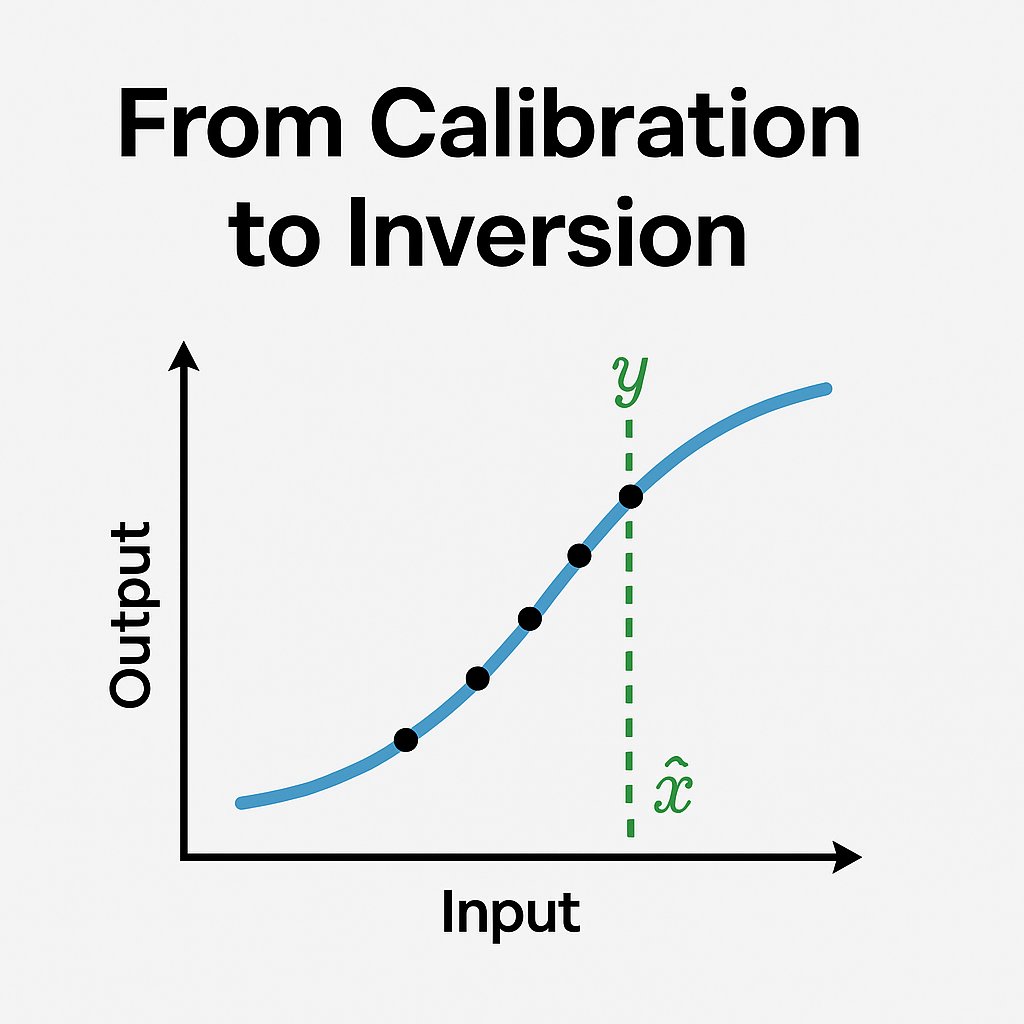
Backwards through the model
measurement
statistics
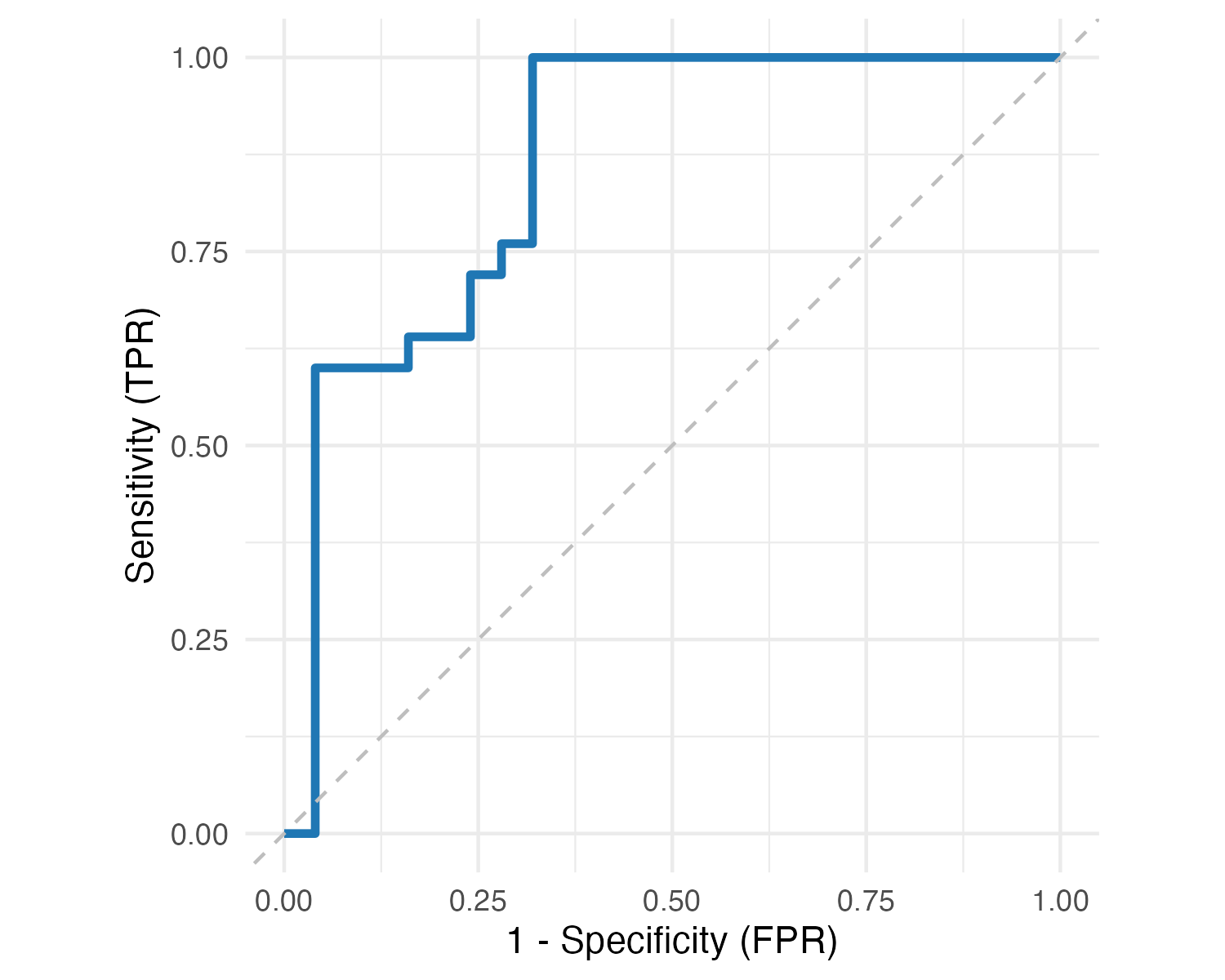
Statistics and Machine Learning: A shared landscape
statistics
machine learning
Supercharge Deep Learning in R with a hybrid R–Colab workflow
machine learning

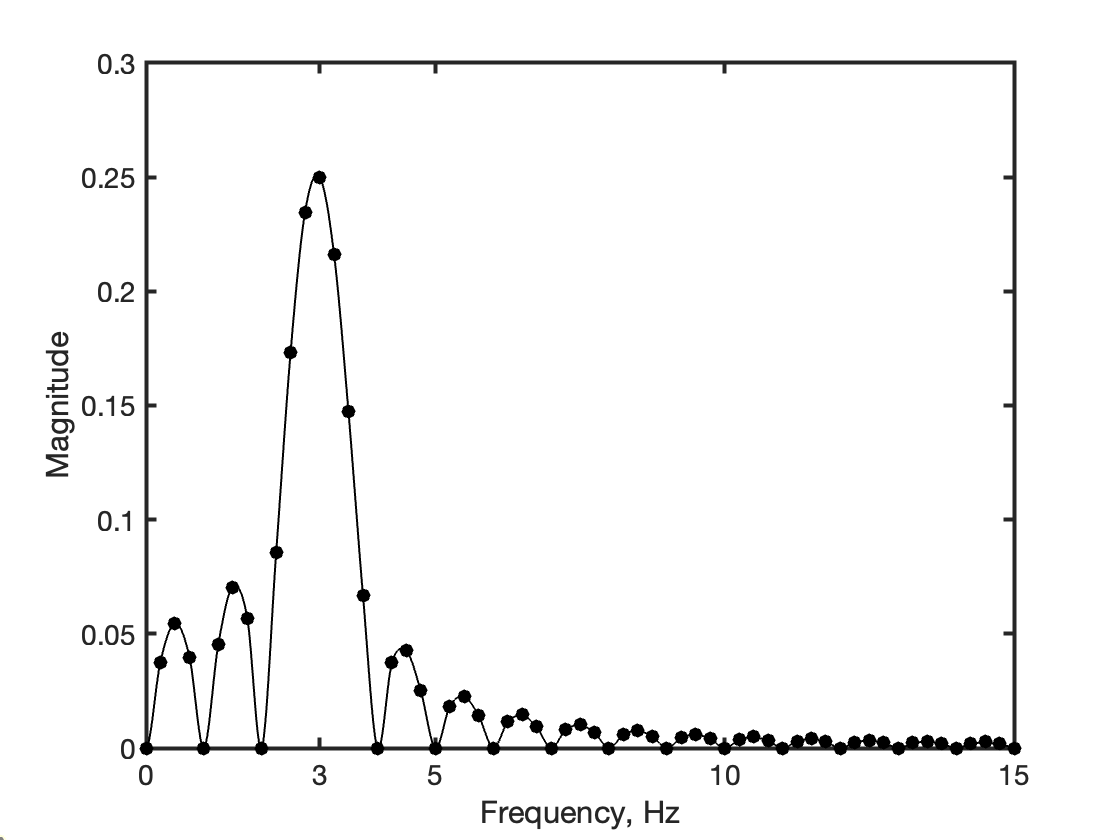
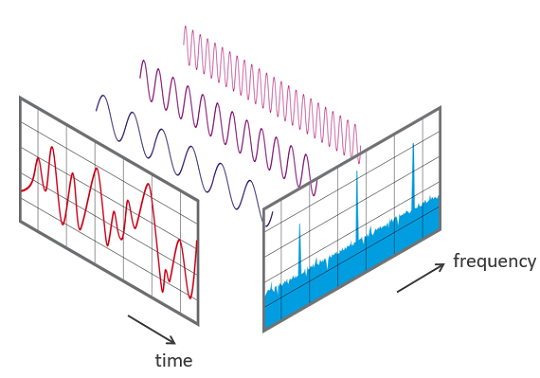
Frequency spectrum of a sine-wave tone burst
signal processing

Spell checking using hunspell
text mining
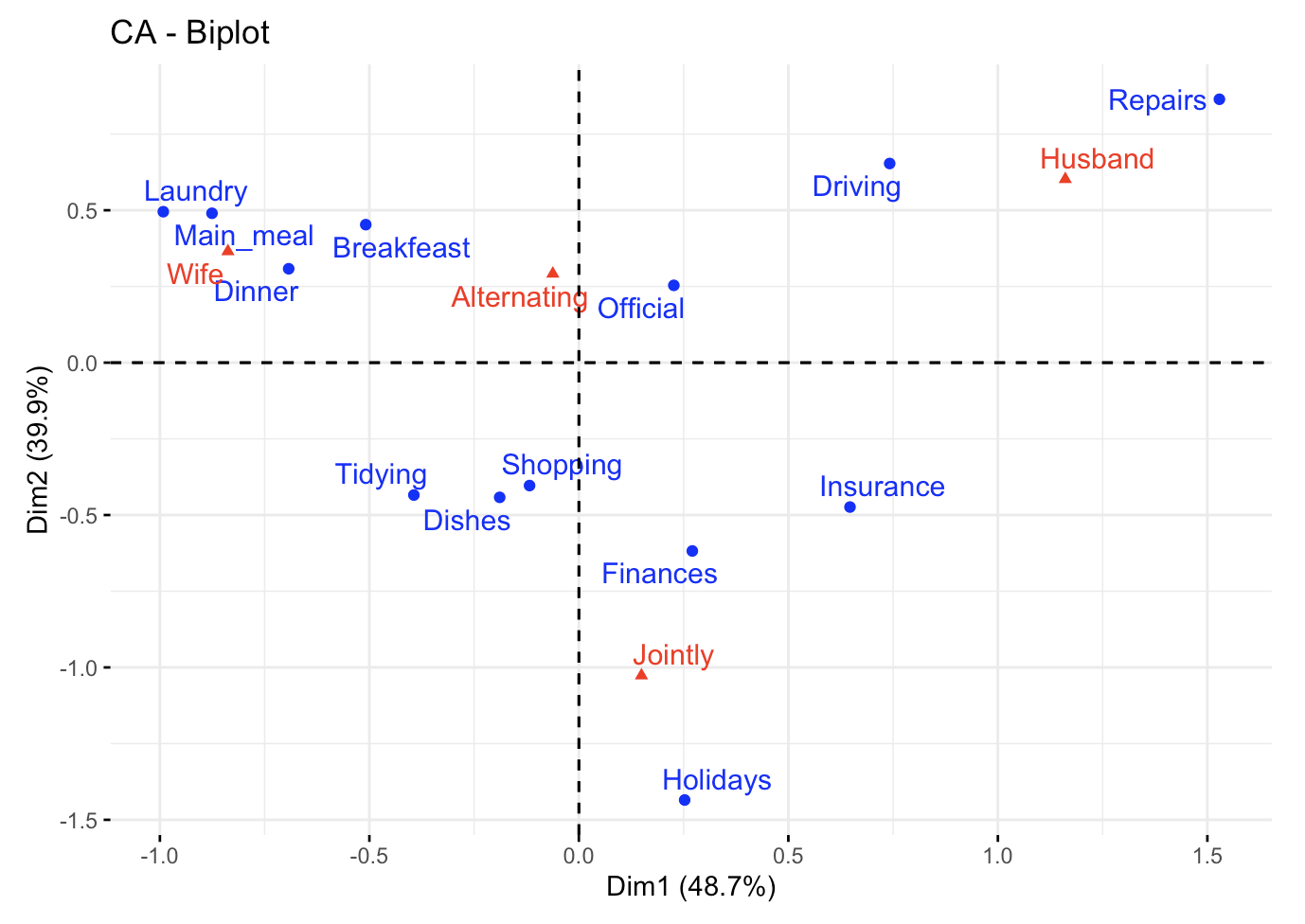
Correspondence analysis: Part II
multivariate statistics
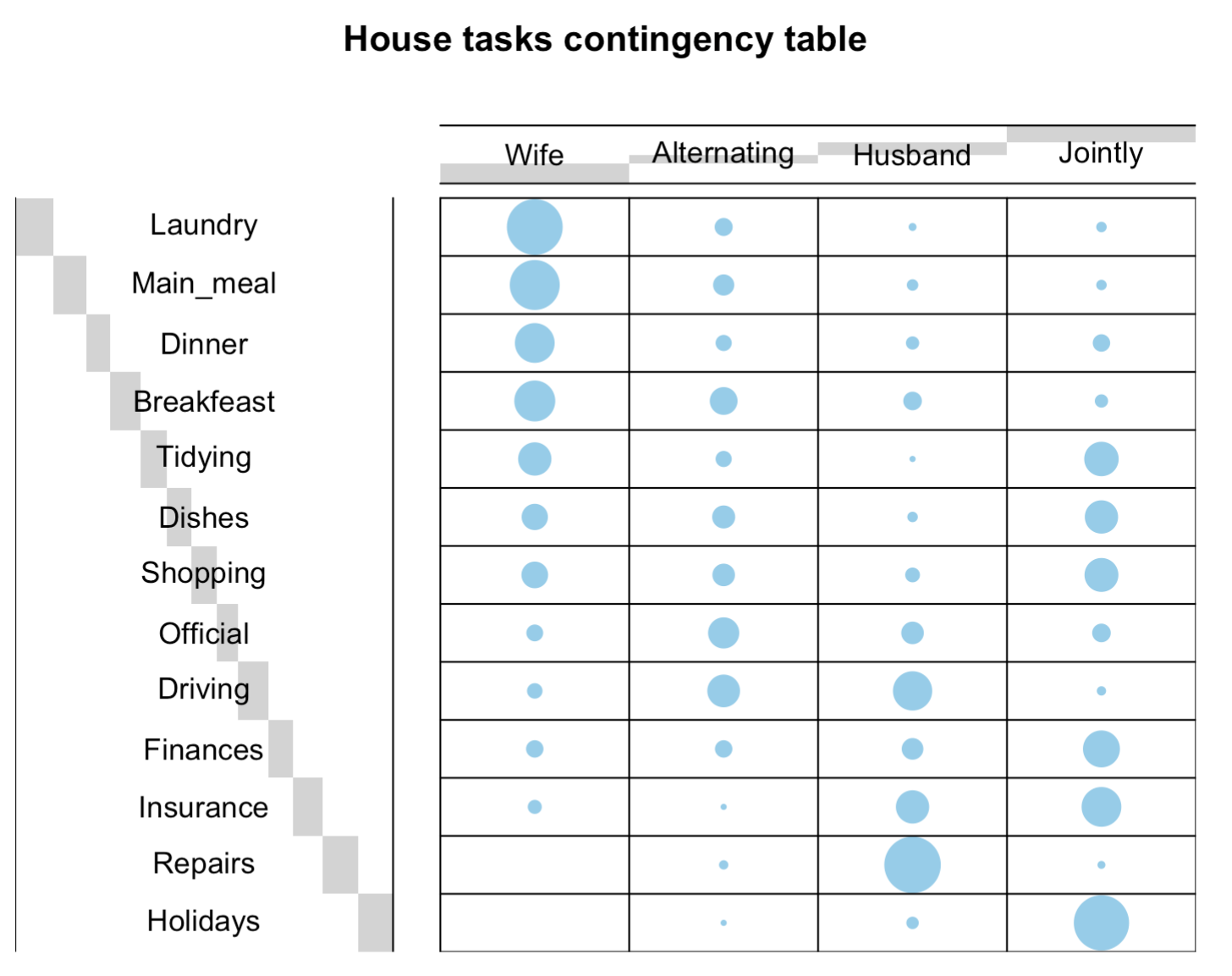
Correspondence analysis: Part I
multivariate statistics

Audio features for free
data mining
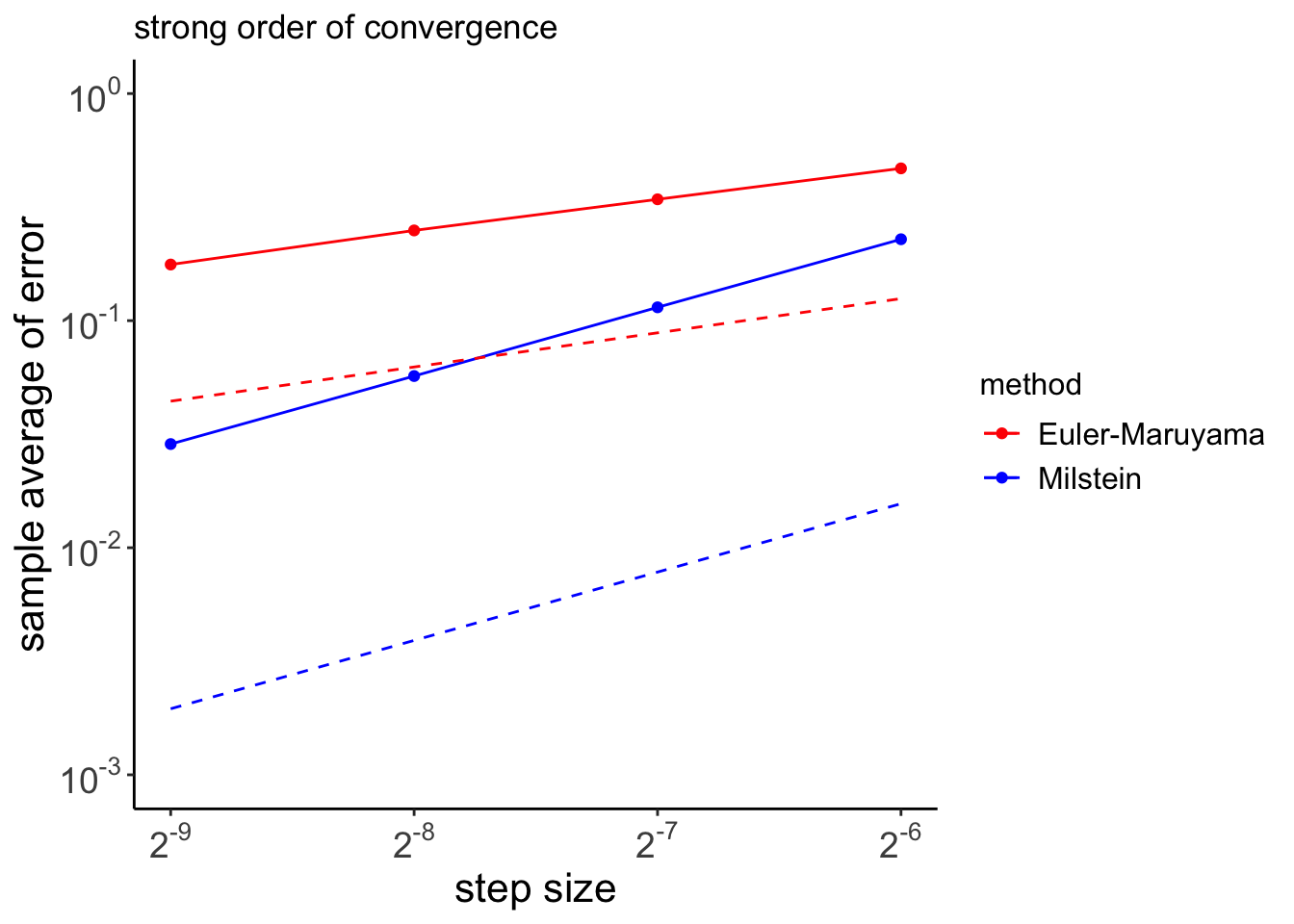

Significant figures
measurement
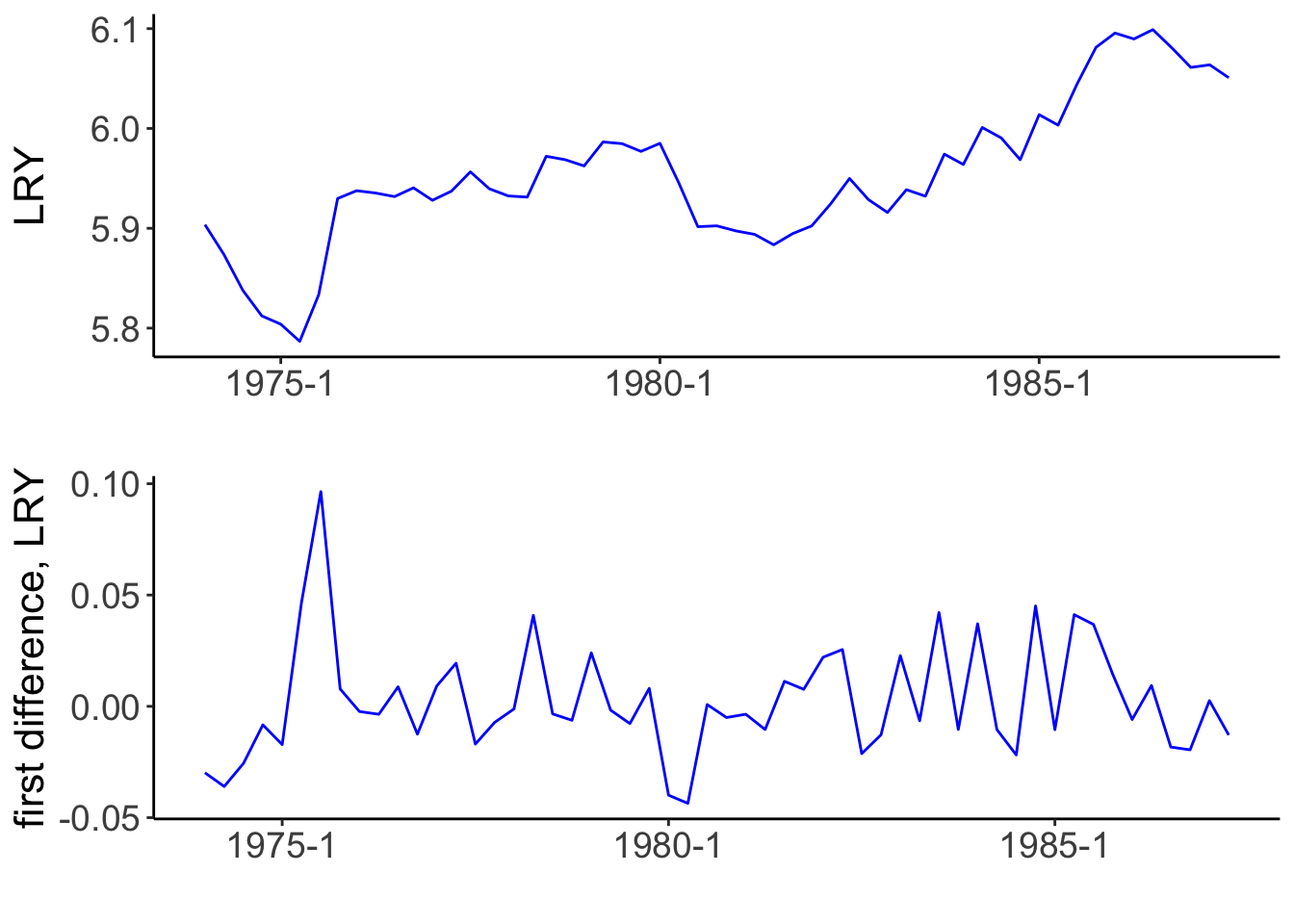
Augmented Dickey-Fuller test
time series
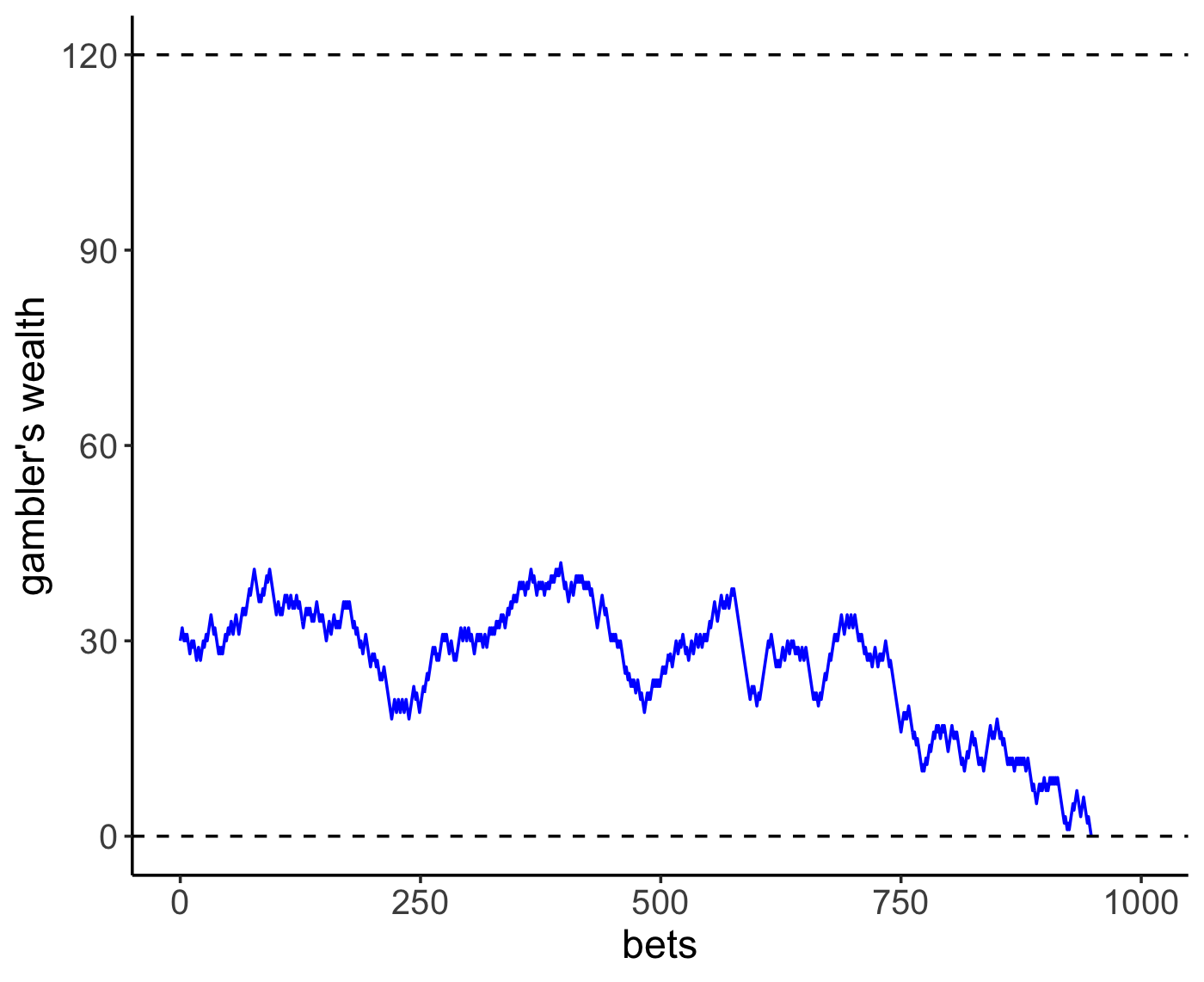
Gambler’s ruin
probability
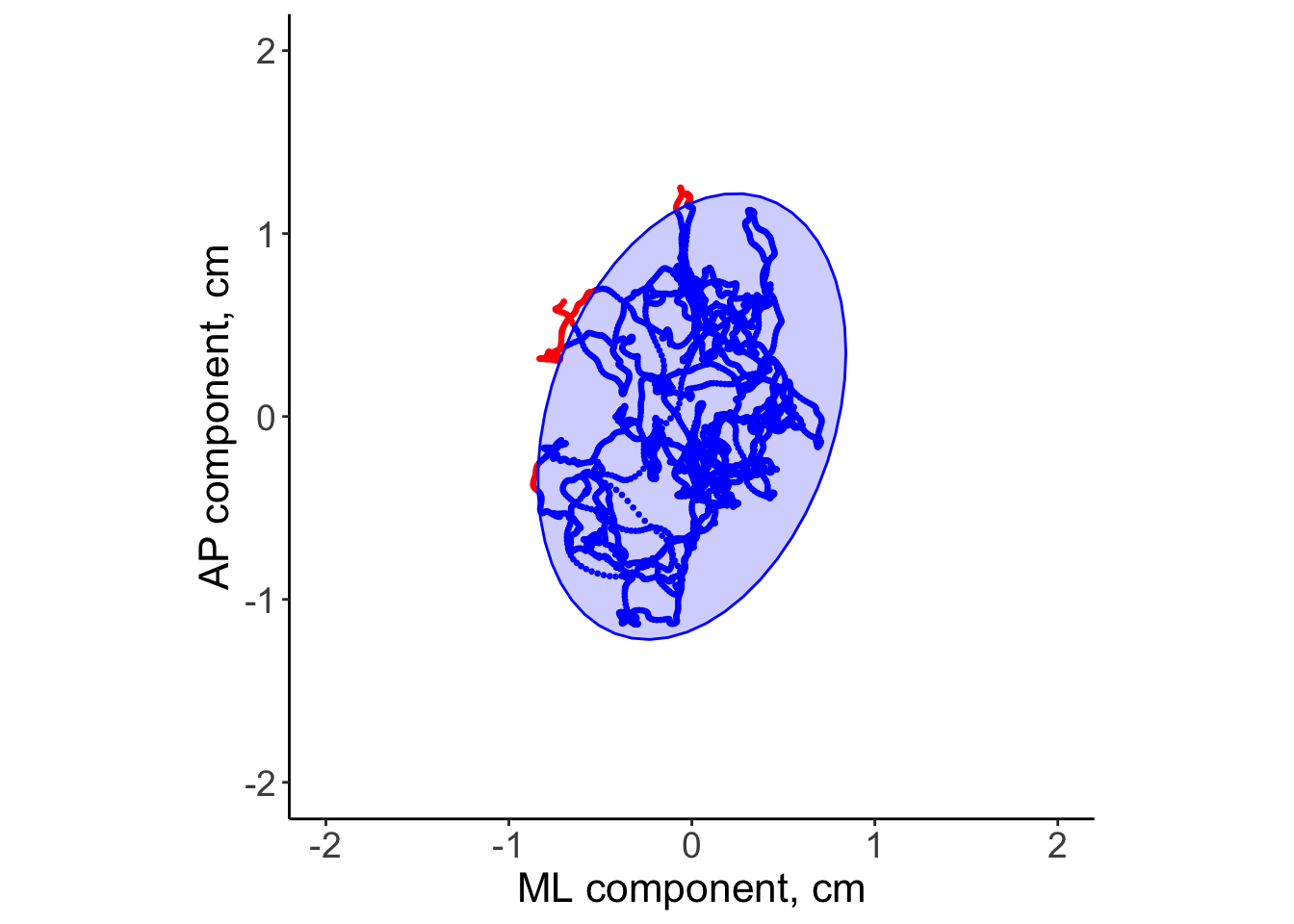
Multivariate probability regions
statistics

Confidence intervals for proportions
statistics


No matching items