Physical systems are rarely memoryless. This post introduces first-order Gauss–Markov (GM1) processes as a bridge between continuous-time physics and discrete-time Kalman filtering. By connecting AR(1) theory with Allan deviation analysis, the discussion shows how temporal correlation alters the statistical meaning of averaging. Through simulations and exact analytical results, the post illustrates why oversampling fails to yield proportionally more independent information when fluctuations possess a finite memory horizon.
The random-walk model introduced in the previous post of this series (here) is often unrealistic for slowly varying quantities. A random walk possesses infinite memory; once a perturbation affects the system, its impact is never fully forgotten. Consequently, the variance grows indefinitely, and the process continuously accumulates uncertainty. Many real physical systems, however, gradually lose memory of past disturbances. Mechanical damping, thermal relaxation, fluid dynamics, electronic feedback, and various dissipative phenomena typically produce stochastic dynamics whose memory fades over time.
The simplest mathematical framework to capture this fading memory is the first-order Gauss-Markov (GM1) process. This model effectively bridges the gap between pure randomness and deterministic decay. Like any first-order Markov process, the GM1 process depends on the past only through its current state, making the future conditionally independent of the remaining history. This property yields a highly tractable linear stochastic differential equation:
\[\dot x(t)=-b\,x(t)+w(t), \tag{1}\]
where \(b>0\) is a damping rate and \(w(t)\) is continuous-time white Gaussian noise with strength \(q\):
In probability theory and statistical physics, this process is commonly known as the Ornstein–Uhlenbeck process, originally introduced to model Brownian motion with friction. In engineering and signal-processing applications, the equivalent formulation is often referred to as a first-order Gauss–Markov process.
The term \(-b\,x(t)\) in Equation 1 continuously pulls the process back toward a mean state, formalizing the concept of thermal relaxation or mechanical damping introduced above. Meanwhile, the stochastic forcing injects random fluctuations into the dynamics. The variance does not grow indefinitely but converges to a finite, stationary value \(\sigma_X^2\), thereby providing a simple model for systems with short-range dependence.
Two important limiting regimes immediately emerge from these expressions. For very small sampling intervals, \(A\approx 1-\Delta T/\tau_c\approx 1\) and \(Q\approx q\,\Delta T\), and the process locally behaves like the random walk introduced in the previous post. Conversely, for sampling intervals much longer than the correlation time, \(A\approx 0\) and \(Q\approx q\tau_c/2\), meaning that consecutive samples progressively lose statistical dependence and the process approaches a memoryless regime.
Kalman estimator
The exact discrete-time representation is particularly useful because it can be incorporated directly into a Kalman-filter (KF) model. The state is not observed directly. Instead, measurements are assumed to be affected by additive Gaussian noise:
After the initial transient, the KF behaves as a stationary recursive estimator with constant asymptotic gain.
From a discrete-time perspective, the sampled GM1 process is equivalent to a first-order autoregressive process, usually denoted AR(1). This equivalence connects the continuous-time physical interpretation of the GM1 process with the classical theory of correlated discrete-time stochastic sequences. Because the discretization is exact, the discrete-time autocorrelation sequence is simply obtained by sampling the continuous-time autocorrelation function of Equation 2:
where \(\phi=\exp(-\Delta T/\tau_c)\). This variance is always larger than in the limiting case \(\phi=0\), corresponding to statistically independent observations. In that case, the classical result is recovered:
\[\mathrm{Var}(\bar X_n)=\frac{q\tau_c}{2n}\]
In practical terms, increasing the sampling frequency within the correlation-time range of the process provides far less independent information than expected under independence assumptions.
Simulation
The discrete-time GM1 model introduced above can be incorporated directly into a scalar Kalman filter. In this simulation, the filter is deliberately matched to the process that generated the data: the same values of \(A, Q, H\), and \(R\) are used both in the simulation model and in the estimator.
This represents the simplest possible scenario. Any discrepancy between the true state and the estimate therefore arises solely from the stochastic uncertainty associated with the process and measurement noise, rather than from model mismatch.
Kalman filter perfectly matched to the Gauss-Markov process
% ********************************% First-order Gauss-Markov process% ********************************b=0.5;% inverse of the correlation time, s^-1 std_x=1;% stationary process standard deviation, [a.u.]dt=1;% sampling time, sT=100;% observation time, sstd_v=1;% measurement error standard deviation, [a.u.]% ***************% Path generation% ***************rng(1250)Ti=2*T;dti=dt;Ni=Ti/dti+1;N=T/dt+1;xi=zeros(Ni,1);A_sim=exp(-b*dti);Q_sim=std_x^2*(1-exp(-2*b*dti));fori=2:Nixi(i) =A_sim*xi(i-1) +randn*sqrt(Q_sim);end% Remove the first half to reduce dependence on initializationx_true=xi((Ni-1)/2+1:dt/dti:end);z_meas=x_true+randn(N,1)*std_v;% *******************% Discrete-time model% *******************A=exp(-b*dt);Q=std_x^2*(1-exp(-2*b*dt));H=1;R=std_v^2;% **************% Initialization% **************x_hat=zeros(N,1);P=zeros(N,1);K=zeros(N,1);x_pred=0;P_pred=std_x^2;fori=1:N% Kalman gainK(i) =P_pred*H/(H*P_pred*H+R);% Measurement updatex_hat(i) =x_pred+K(i)*(z_meas(i) -H*x_pred);P(i) = (1-K(i)*H)*P_pred;% Predictionx_pred=A*x_hat(i);P_pred=A*P(i)*A+Q;end% ************% Error plot% ************figureplot(0:N-1,x_hat-x_true,'b','LineWidth',1.5)holdonplot(0:N-1,2*sqrt(P),'k--',...0:N-1,-2*sqrt(P),'k--','LineWidth',1.5)xlabel('Steps')ylabel('Error state [a.u.]')set(gca,'FontSize',14,'LineWidth',2)% ****************% Kalman gain plot% ****************figureplot(0:N-1,K,'b','LineWidth',2)xlabel('Steps')ylabel('Kalman gain')ylim([00.55])set(gca,'FontSize',14,'LineWidth',2)
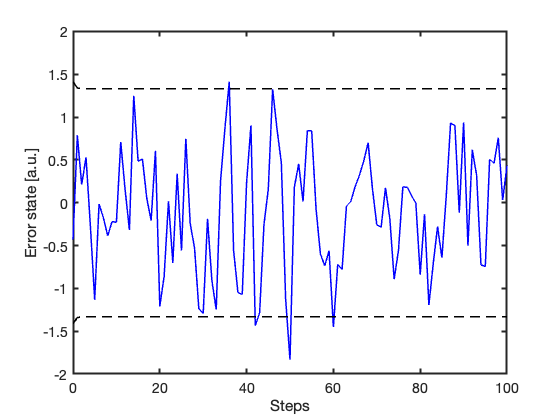
Figure 1 shows the estimation error together with the approximate 95% confidence bounds predicted by the KF. After the initial transient, the error behaves as expected for a correctly specified model: it fluctuates around zero and mostly remains within the predicted uncertainty bounds.
Figure 1: Estimation error and approximate 95% confidence bounds predicted by the KF (\(\pm 2\sqrt{P_k}\)). After the initial transient, the error remains mostly confined within the uncertainty interval associated with the estimated covariance.
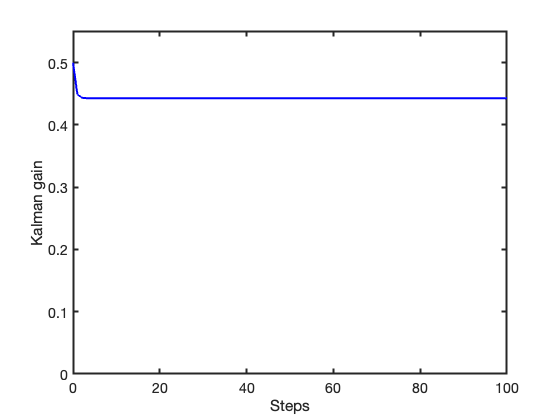
Figure 2 shows the corresponding Kalman gain. After a short transient, the gain reaches a steady-state value, reflecting the stationary nature of the underlying process and the steady balance between prediction and measurement uncertainty.
Figure 2: Evolution of the Kalman gain.
For the parameters used in this simulation (\(b=0.5\,\mathrm{s}^{-1}\), \(\Delta t=1\,\mathrm{s}\), \(\sigma_X=1\,\mathrm{a.u.}\), and \(R=1\,(\mathrm{a.u.})^2\)), the scalar Riccati equation (Equation 4) predicts a steady-state covariance (Equation 5) and Kalman gain (Equation 6) with the same numerical value, although the associated physical units differ:
\[P_\infty=K_\infty \approx 0.443.\]
This result is in excellent agreement with the simulated gain trajectory shown in Figure 2. The equality \(P_\infty=K_\infty\) follows here from the scalar structure of the problem with \(H=1\) and \(R=1\).
Probing the environment
The GM1 process introduced above should not be regarded merely as a convenient mathematical model. In many sensing applications, temporally correlated fluctuations are not simply a nuisance: they are the signature of the physical medium being observed.
A barometric pressure sensor, for example, does not only measure the electronic noise of its readout chain. It also responds to slow pressure fluctuations, thermal effects, air motion, and environmental dynamics. Similarly, an ultrasonic time-of-flight system probes a propagation medium whose temperature, humidity, turbulence, and local gradients affect the measured delay.
In this sense, many sensors act as environmental probes. Their output reflects not only the sensor itself, but also the dynamics of the surrounding medium, which often evolves over finite correlation times.
The key point is that correlated noise is not always “bad noise”. Sometimes it is the phenomenon of interest. Rather than averaging it away blindly, it is often more informative to characterize its temporal structure. From a measurement perspective, a related question is how much independent information is actually gained by sampling faster: is oversampling really a good recipe to improve signal-to-noise ratio?
Allan deviation as a multiscale diagnostic tool
Allan deviation provides exactly the multiscale view we need to reveal how variability changes across different averaging times. Originally introduced in the context of oscillator stability analysis, it is now routinely used to characterize temporally correlated stochastic processes across many areas of measurement science and signal processing.
The following simulation reproduces a long-duration acquisition from a stationary GM1 process with correlation time \(\tau_c=1\,\mathrm{s}\). The process is sampled every \(T_s = 20\,\mathrm{ms},\) corresponding to an oversampling ratio of 50 samples per correlation time. The total observation time is approximately three hours (about 175 minutes), yielding a record of \(2^{19}\) samples. A white Gaussian sequence with the same stationary variance is generated as a reference. This allows the Allan-deviation analysis to isolate the effects of temporal correlation from those associated solely with signal variance.
Simulation of a long-term recording for Allan deviation analysis
% ***************************************% GM1 signal for Allan deviation analysis% ***************************************clearclccloseallrng(2026)% Physical / stochastic parameterstau=1;% correlation time [s]std_y=1;% stationary standard deviation [a.u.]osr=50;% samples per correlation timeTs=tau/osr;Fs=1/Ts;N=2^19;% number of samplest= (0:N-1)'*Ts;% Exact discrete-time GM1 modelF=exp(-Ts/tau);Q=std_y^2*(1-F^2);y=zeros(N,1);% Start at stationarityy(1) =std_y*randn;fork=2:Ny(k) =F*y(k-1) +sqrt(Q)*randn;end% White input sequence with same stationary variance for comparisonu=std_y*randn(N,1);% Basic checksfprintf('Sampling interval Ts = %.4g s\n',Ts)fprintf('Observation time = %.2f h\n',N*Ts/3600)fprintf('Correlation time tau = %.4g s\n',tau)fprintf('Empirical var white = %.4g (a.u.)^2\n',var(u))fprintf('Empirical var GM1 = %.4g (a.u.)^2\n',var(y))% Save for Allan analyzersave('allan_signals_gm1.mat','u','y','t','Ts','Fs','tau','std_y','F','Q')% Quick visualizationfigureplot(t(1:5000),u(1:5000),'Color', [0.60.60.6])holdonplot(t(1:5000),y(1:5000),'b','LineWidth',1.2)xlabel('Time [s]')ylabel('Amplitude [a.u.]')legend('white input','GM1 output')set(gca,'FontSize',14,'LineWidth',1.5)
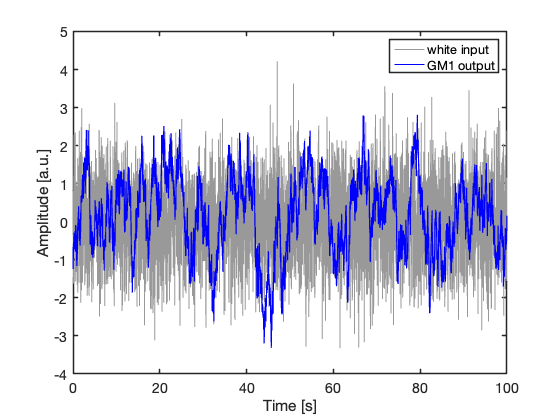
The GM1 process can be interpreted as the output of a first-order stochastic shaping filter driven by white Gaussian noise. Figure 3 compares a short segment of the reference white-noise sequence with the corresponding correlated GM1 output generated by the discrete-time model. Although the two processes have approximately the same variance, their temporal structure is markedly different. The GM1 process appears visibly smoother because its dynamics suppress rapid fluctuations and introduce finite temporal correlation. This apparent smoothness should not be confused with a larger amount of independent information. Samples acquired within a correlation time remain strongly redundant, even when the signal appears less noisy.
Figure 3: Short segment of the simulated white-noise input and corresponding GM1 output.
Allan deviation analysis
% ************************% Allan deviation analysis% ************************clearclccloseallload('allan_signals_gm1.mat')% Cluster sizes: powers of twoN=length(u);maxM=floor(N/8);m=2.^(0:floor(log2(maxM)));% Allan variance[avar_u,tau_u] =allanvar(u,m,Fs);[avar_y,tau_y] =allanvar(y,m,Fs);adev_u=sqrt(avar_u);adev_y=sqrt(avar_y);% Approximate number of Allan clustersM=floor(N./m) -1;% Fit regionsidx_white=tau_u>=0.02&tau_u<=0.5;idx_gm1_short=tau_y>=0.02&tau_y<=0.5;idx_gm1_long=tau_y>=20&tau_y<=500;% Log-log weighted linear regression helperfit_loglog=@(tau,adev,idx,M) fitlm( ...log10(tau(idx)),...log10(adev(idx)),...'linear',...'Weights',M(idx));mdl_white=fit_loglog(tau_u,adev_u,idx_white,M);mdl_gm1_short=fit_loglog(tau_y,adev_y,idx_gm1_short,M);mdl_gm1_long=fit_loglog(tau_y,adev_y,idx_gm1_long,M);% Extract slopes and confidence intervalsci_white=coefCI(mdl_white);ci_gm1_short=coefCI(mdl_gm1_short);ci_gm1_long=coefCI(mdl_gm1_long);fprintf('White input slope = %.3f, 95%% CI [%.3f, %.3f]\n',...mdl_white.Coefficients.Estimate(2),ci_white(2,1),ci_white(2,2))fprintf('GM1 short-time slope = %.3f, 95%% CI [%.3f, %.3f]\n',...mdl_gm1_short.Coefficients.Estimate(2),ci_gm1_short(2,1),ci_gm1_short(2,2))fprintf('GM1 long-time slope = %.3f, 95%% CI [%.3f, %.3f]\n',...mdl_gm1_long.Coefficients.Estimate(2),ci_gm1_long(2,1),ci_gm1_long(2,2))% Fitted linestau_fit_white=tau_u(idx_white);fit_white=10.^predict(mdl_white,log10(tau_fit_white));tau_fit_gm1_short=tau_y(idx_gm1_short);fit_gm1_short=10.^predict(mdl_gm1_short,log10(tau_fit_gm1_short));tau_fit_gm1_long=tau_y(idx_gm1_long);fit_gm1_long=10.^predict(mdl_gm1_long,log10(tau_fit_gm1_long));% AR(1) theoretical Allan deviationphi=F;sigma2=std_y^2;n=m(:);tau_avg=n*Ts;var_mean=zeros(size(n));forii=1:numel(n)h= (1:n(ii)-1)';var_mean(ii) =sigma2/n(ii)^2*... (n(ii) +2*sum((n(ii)-h).*phi.^h));endcov_adj=sigma2./n.^2.*...phi.* (1-phi.^n).^2./ (1-phi)^2;avar_theory=var_mean-cov_adj;adev_theory=sqrt(avar_theory);% ************% Final figure% ************figureh_fit_white=loglog(tau_fit_white,fit_white,...'r','LineWidth',2);holdonh_theory=loglog(tau_avg,adev_theory,...'k','LineWidth',1);h_fit_gm1_short=loglog(tau_fit_gm1_short,fit_gm1_short,...'r','LineWidth',2);loglog(tau_fit_gm1_long,fit_gm1_long,...'r','LineWidth',2);h_white=loglog(tau_u,adev_u,...'k.','MarkerSize',24);h_gm1=loglog(tau_y,adev_y,...'b.','MarkerSize',24);gridonax=gca;ax.XMinorGrid='off';ax.YMinorGrid='off';ax.GridAlpha=0.15;xlabel('Averaging time \tau [s]')ylabel('Allan deviation')legend([h_white,h_gm1,h_fit_white,h_theory],... {'white input',...'GM1 output',...'log-log fits',...'AR(1) theory'},...'Location','southwest')set(gca,'FontSize',14,'LineWidth',1.5)
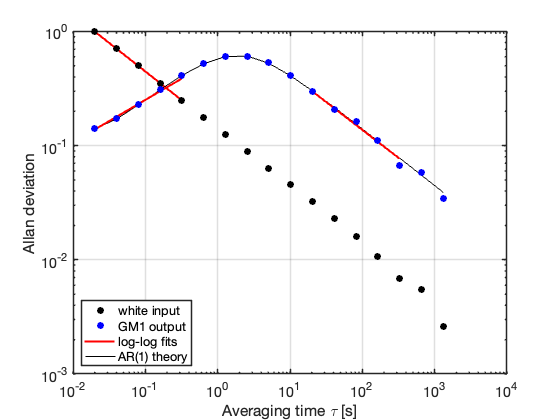
The Allan-deviation curves obtained from the simulated sequences are shown in Figure 4.
Figure 4: Allan-deviation comparison between white noise and a GM1 process with correlation time \(\tau_c = 1\,\mathrm{s}\). Red segments indicate local log–log regressions used for slope estimation, while the solid black curve represents the theoretical AR(1) prediction.
Several features of temporal correlation become immediately apparent.
For the white-noise input, the Allan deviation follows the familiar power law
\[\sigma_A(\tau) \propto \tau^{-1/2},\]
indicating that longer averaging times continuously increase the amount of statistically independent information available through averaging. The corresponding log–log regression yields a slope of \(-0.500\) (\(95\%\) CI \([-0.502,-0.497]\)), in excellent agreement with the theoretical value \(-1/2\).
The GM1 process behaves very differently. At short averaging times, its Allan deviation lies below the white-noise reference because the first-order dynamics suppress rapid fluctuations and smooth the process locally. However, as the averaging time approaches the correlation-time region, the effects of temporal memory progressively dominate the averaging process.
In this regime, consecutive observations no longer behave as statistically independent measurements. The Allan-deviation curve departs from the white-noise scaling law and exhibits a markedly different slope structure. The short-time log–log regression yields a positive slope of \(0.371\) (\(95\%\) CI \([0.296,0.446]\)), directly reflecting the fact that local oversampling is collecting strongly correlated information rather than statistically independent samples. In other words, additional samples are being acquired faster than new independent information is being generated by the underlying process.
Only for averaging times significantly longer than the correlation time does the process progressively recover a white-noise-like averaging behavior. In this asymptotic regime, the long-time slope approaches the classical \(-1/2\) value expected for effectively decorrelated observations. The corresponding regression yields a slope of \(-0.489\) (\(95\%\) CI \([-0.582,-0.395]\)).
The theoretical Allan-deviation curve derived from the equivalent AR(1) representation closely matches the simulated GM1 behavior across all averaging scales, confirming the exact equivalence between the sampled Gauss–Markov process and its discrete-time autoregressive representation.
A closer look at Allan averaging
The Allan variance can be interpreted in a particularly illuminating way when the underlying process possesses temporal correlation.
For a sequence divided into adjacent blocks of length \(n\), define the local averages
\[\bar x_{1,n}=\frac1n\sum_{k=1}^n x_k,\]
and
\[\bar x_{2,n}=\frac1n\sum_{k=n+1}^{2n} x_k.\]
The Allan variance is constructed from the squared difference between consecutive local averages:
This expression provides a remarkably intuitive interpretation of Allan variance. The first term, \(\mathrm{Var}(\bar X_n),\) describes the uncertainty reduction produced by averaging. The second term, \(\mathrm{Cov}(\bar X_{1,n},\bar X_{2,n}),\) measures the temporal redundancy that survives between adjacent local averages.
For white noise, adjacent averages are statistically independent and the covariance term vanishes. Allan averaging therefore behaves exactly as expected from the familiar \(1/\sqrt{n}\) law. For correlated processes such as GM1 or AR(1), however, adjacent averages remain statistically dependent over time scales comparable with the correlation time.
This expression reveals that Allan variance is not simply the variance of a sample mean. A correlated process may even exhibit a smaller Allan deviation than white noise over some averaging ranges. This does not imply that more independent information is being collected. Rather, it reflects the fact that temporal correlation smooths short-term fluctuations while simultaneously increasing redundancy between neighboring samples.
The key question is therefore not how small the Allan deviation becomes at a particular averaging time, but how efficiently additional averaging continues to reduce uncertainty.
Concluding remarks
At first sight, averaging appears to be a straightforward recipe for reducing uncertainty: collect more samples, average them, and the noise decreases. This intuition is perfectly valid when observations are statistically independent. However, many real-world processes possess temporal memory, and successive samples may carry strongly redundant information.
The first-order Gauss–Markov process provides a simple yet powerful framework for describing this behavior. Through its finite correlation time, it bridges the gap between purely random fluctuations and deterministic dynamics, while remaining mathematically tractable and directly compatible with Kalman filtering.
The analysis based on Allan deviation highlights an important consequence of temporal correlation. Two processes may exhibit the same variance while carrying very different amounts of independent information across time. In such situations, increasing the sampling frequency does not necessarily yield the statistical benefits predicted by classical independence assumptions.
Understanding how uncertainty, correlation, and information evolve across time scales is therefore just as important as understanding the magnitude of the fluctuations themselves. In many measurement problems, the key question is not simply how noisy a signal is, but how much new information each additional sample actually provides.