Code
# Libraries
library(tidyverse)
library(gplots)
library(corrplot)
library(factoextra)
library(kableExtra) Correspondence Analysis (CA) is a type of multidimensional scaling, one of several methods that are available for developing spatial models that reveal associations between two or more categorical variables. If data of only two variables are involved, the method is usually called Simple Correspondence Analysis (SCA); if data of more than two variables are considered in the dataset, then the method is usually called Multiple Correspondence Analysis (MCA).
SCA is often used in combination with a standard chi-squared test of independence for two categorical variables that form a contingency table. We recall that a contingency table displays frequencies for combinations of two categorical variables; analysts also refer to contingency tables as crosstabulation and two-way tables. Contingency tables classify outcomes for one variable in rows and the other in columns. The values at the row and column intersections are frequencies for each unique combination of the two variables. These values can suggest whether or not the two variables are correlated.
# Libraries
library(tidyverse)
library(gplots)
library(corrplot)
library(factoextra)
library(kableExtra) housetasks, available in the package factoextra, is a data frame that contains the frequency of execution of 13 house tasks performed by the couple in four different ways: a) the wife only; b) alternatively; c) the husband only; d) jointly.
data(housetasks)
housetasks %>%
kable(
align = "rrrr",
col.names = c("Wife", "Alternating", "Husband", "Jointly"),
caption = "House tasks contingency table",
) %>%
kable_classic()| Wife | Alternating | Husband | Jointly | |
|---|---|---|---|---|
| Laundry | 156 | 14 | 2 | 4 |
| Main_meal | 124 | 20 | 5 | 4 |
| Dinner | 77 | 11 | 7 | 13 |
| Breakfeast | 82 | 36 | 15 | 7 |
| Tidying | 53 | 11 | 1 | 57 |
| Dishes | 32 | 24 | 4 | 53 |
| Shopping | 33 | 23 | 9 | 55 |
| Official | 12 | 46 | 23 | 15 |
| Driving | 10 | 51 | 75 | 3 |
| Finances | 13 | 13 | 21 | 66 |
| Insurance | 8 | 1 | 53 | 77 |
| Repairs | 0 | 3 | 160 | 2 |
| Holidays | 0 | 1 | 6 | 153 |
To easily interpret the contingency table, a graphical matrix can be drawn using the function balloonplot() from the gplots package. In this graph, each cell contains a dot whose size reflects the relative magnitude of the value it contains.
# Convert the data frame to a table
dt <- as.table(as.matrix(housetasks))
# Graph
balloonplot(t(dt), main = "House tasks contingency table", xlab = "", ylab = "",
label = FALSE, show.margins = FALSE)
Let us consider a generic two-dimensional contingency table \(\bf{T}\), having \(R\) rows (corresponding to the levels of the categorical variable \(X\)) and \(C\) columns (corresponding to the levels of the categorical variable \(Y\)). The table is built based on a dataset of \(n\) observations, which are distributed across the \(R\cdot C\) cells of \(\bf{T}\). Each cell shows the count \(n_{ij},\,i=1,\cdots,R;\,j=1,\cdots,C\).
Row marginals
The row marginals (or row margins) can be computed by taking the row sums of the counts \(n_{ij}\):
\[ n_{i+}=\sum_{j=1}^C n_{ij},\;i=1,\dots,R \]
Column marginals
The column marginals (or col margins) can be computed by taking the column sums of the counts \(n_{ij}\):
\[ n_{+j}=\sum_{i=1}^R n_{ij}\;j=1,\dots,C \]
Grand total
The gran total is the complete number after everything has been added up:
\[ n_{++}=\sum_{i=1}^R n_{i+}=\sum_{j=1}^Cn_{+j}=\sum_{i=1}^R\sum_{j=1}^Cn_{ij}=n \]
# Row marginals
row.sum <- apply(housetasks, 1, sum)
# Column marginals
col.sum <- apply(housetasks, 2, sum)
# Gran total
n <- sum(housetasks)
housetasks %>%
mutate(total = row.sum) %>%
rbind("Total" = c(col.sum, n)) %>%
kable(
align = "rrrrr",
col.names = c("Wife", "Alternating", "Husband", "Jointly", "Total"),
caption = "House task contingency table with row, column margins and gran total",
) %>%
kable_classic()| Wife | Alternating | Husband | Jointly | Total | |
|---|---|---|---|---|---|
| Laundry | 156 | 14 | 2 | 4 | 176 |
| Main_meal | 124 | 20 | 5 | 4 | 153 |
| Dinner | 77 | 11 | 7 | 13 | 108 |
| Breakfeast | 82 | 36 | 15 | 7 | 140 |
| Tidying | 53 | 11 | 1 | 57 | 122 |
| Dishes | 32 | 24 | 4 | 53 | 113 |
| Shopping | 33 | 23 | 9 | 55 | 120 |
| Official | 12 | 46 | 23 | 15 | 96 |
| Driving | 10 | 51 | 75 | 3 | 139 |
| Finances | 13 | 13 | 21 | 66 | 113 |
| Insurance | 8 | 1 | 53 | 77 | 139 |
| Repairs | 0 | 3 | 160 | 2 | 165 |
| Holidays | 0 | 1 | 6 | 153 | 160 |
| Total | 600 | 254 | 381 | 509 | 1744 |
The gran total is obtained by summing the values of the row margin or the values of the col margin (\(n=\) 1744).
To compare rows (or columns), their profiles can be analyzed, in the search for similar rows (or columns).
Row profile
The profile of a row (or row profile) is calculated by taking each row point and dividing by the corresponding value of the row margin:
\[ \underline{a}_i,\;i=1,\dots,R=\{\underline{a}_{i_j},\;j=1,\dots,C\}=\{n_{ij}/n_{i+},\;j=1,\dots,C\} \]
Average row profile
The average row profile can be computed from the col margin after dividing it by the grand total:
\[ \underline{r}=\{r_j=n_{+j}/n,\;j=1,\dots,C\} \]
# Row profile
row.profile <- housetasks/row.sum
# Average row profile
average.row.profile <- col.sum/n
# Row margins
row.profile.sum <- apply(row.profile, 1, sum)
row.profile %>%
mutate(TOTAL = row.profile.sum) %>%
rbind(`Average row profile` = c(average.row.profile, sum(average.row.profile))) %>%
kable(
align = "rrrrr",
col.names = c("Wife", "Alternating", "Husband", "Jointly", "Total"),
digits = 4,
caption = "House tasks data frame with row profiles and average row profile",
) %>%
kable_classic()| Wife | Alternating | Husband | Jointly | Total | |
|---|---|---|---|---|---|
| Laundry | 0.8864 | 0.0795 | 0.0114 | 0.0227 | 1 |
| Main_meal | 0.8105 | 0.1307 | 0.0327 | 0.0261 | 1 |
| Dinner | 0.7130 | 0.1019 | 0.0648 | 0.1204 | 1 |
| Breakfeast | 0.5857 | 0.2571 | 0.1071 | 0.0500 | 1 |
| Tidying | 0.4344 | 0.0902 | 0.0082 | 0.4672 | 1 |
| Dishes | 0.2832 | 0.2124 | 0.0354 | 0.4690 | 1 |
| Shopping | 0.2750 | 0.1917 | 0.0750 | 0.4583 | 1 |
| Official | 0.1250 | 0.4792 | 0.2396 | 0.1562 | 1 |
| Driving | 0.0719 | 0.3669 | 0.5396 | 0.0216 | 1 |
| Finances | 0.1150 | 0.1150 | 0.1858 | 0.5841 | 1 |
| Insurance | 0.0576 | 0.0072 | 0.3813 | 0.5540 | 1 |
| Repairs | 0.0000 | 0.0182 | 0.9697 | 0.0121 | 1 |
| Holidays | 0.0000 | 0.0063 | 0.0375 | 0.9562 | 1 |
| Average row profile | 0.3440 | 0.1456 | 0.2185 | 0.2919 | 1 |
Column profile
The profile of a column (or col profile) is calculated by taking each column point and dividing by the corresponding value of the col margin:
\[ \underline{b}_j,\;j=1,\dots,C=\{\underline{b}_{j_i},\;i=1,\dots,R\}=\{n_{ij}/n_{+j},\;i=1,\dots,R\} \]
Average column profile
The average column profile (or average col profile) can be computed from the row marginal after dividing it by the grand total:
\[ \underline{c}=\{c_i=n_{i+}/n,\;i=1,\dots,R\} \]
# Column profile
col.profile <- t(housetasks)/col.sum
col.profile <- as.data.frame(t(col.profile))
# Average column profile
average.col.profile <- row.sum/n
# Column margins
col.profile.sum <- apply(col.profile, 2, sum)
col.profile %>%
mutate(`Average col profile` = average.col.profile) %>%
rbind(Total = c(col.profile.sum, sum(average.col.profile))) %>%
kable(
align = "rrrrr",
col.names = c("Wife", "Alternating", "Husband", "Jointly", "Average col profile"),
digits = 4,
caption = "House tasks data frame with col profiles and average col profile",
) %>%
kable_classic()| Wife | Alternating | Husband | Jointly | Average col profile | |
|---|---|---|---|---|---|
| Laundry | 0.2600 | 0.0551 | 0.0052 | 0.0079 | 0.1009 |
| Main_meal | 0.2067 | 0.0787 | 0.0131 | 0.0079 | 0.0877 |
| Dinner | 0.1283 | 0.0433 | 0.0184 | 0.0255 | 0.0619 |
| Breakfeast | 0.1367 | 0.1417 | 0.0394 | 0.0138 | 0.0803 |
| Tidying | 0.0883 | 0.0433 | 0.0026 | 0.1120 | 0.0700 |
| Dishes | 0.0533 | 0.0945 | 0.0105 | 0.1041 | 0.0648 |
| Shopping | 0.0550 | 0.0906 | 0.0236 | 0.1081 | 0.0688 |
| Official | 0.0200 | 0.1811 | 0.0604 | 0.0295 | 0.0550 |
| Driving | 0.0167 | 0.2008 | 0.1969 | 0.0059 | 0.0797 |
| Finances | 0.0217 | 0.0512 | 0.0551 | 0.1297 | 0.0648 |
| Insurance | 0.0133 | 0.0039 | 0.1391 | 0.1513 | 0.0797 |
| Repairs | 0.0000 | 0.0118 | 0.4199 | 0.0039 | 0.0946 |
| Holidays | 0.0000 | 0.0039 | 0.0157 | 0.3006 | 0.0917 |
| Total | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
Distance (or similarity) between row profiles
This metrics is useful to compare how similar to each other are two rows of the contingency table:
\[ d^2_{kl},\;k,l=1,\dots,R=\Vert \underline{a}_k-\underline{a}_{l}\Vert^2_\underline{r}=\large\sum_{j=1}^C\dfrac{(\underline{a}_{k_j}-\underline{a}_{l_j})^2}{r_j} \]
Recall that we need to normalize each component within the sum to the corresponding element of the average row profile.
# "Dinner" and "Driving" profiles
dinner.p <- row.profile["Dinner", ]
driving.p <- row.profile["Driving", ]
# Distance between "Dinner" and "Driving"
d2_1 <- sum(((dinner.p - driving.p)^2)/average.row.profile)
# "Breakfeast" profile
breakfast.p <- row.profile["Breakfeast", ]
# Distance between "Dinner" and "Breakfeast"
d2_2 <- sum(((dinner.p - breakfast.p)^2)/average.row.profile)Example - The similarity between “Dinner” and “Driving” profiles is 2.742, whereas the similarity between “Dinner” and “Breakfeast” is 0.238.
Distance (or similarity) between col profiles
This metrics is useful to compare how similar to each other are two columns of the contingency table:
\[ d^2_{kl},\;k,l=1,\dots,C=\Vert \underline{b}_k-\underline{b}_l\Vert^2_\underline{c}=\large\sum_{i=1}^R\dfrac{(\underline{b}_{k_i}-\underline{b}_{l_i})^2}{c_i} \]
Recall that we need to normalize each component within the sum to the corresponding element of the average col profile.
# "Wife" and "Husband" profiles
wife.p <- col.profile[, "Wife"]
husband.p <- col.profile[, "Husband"]
# Distance between "Wife" and "Husband"
d2_1 <- sum(((wife.p - husband.p)^2) / average.col.profile)
# "Jointly" profile
jointly.p <- col.profile[, "Jointly"]
# Distance between "Wife" and "Jointly"
d2_2 <- sum(((wife.p - jointly.p)^2) / average.col.profile)Example - The similarity between “Wife” and “Husband” profiles is 4.05, whereas the similarity between “Wife” and “Jointly” is 2.935.
Distance (or similarity) between each row profile and the average row profile
This metrics is useful to compare how similar to the average row profile is any row profile.
\[ d^2_{k},\;k=1,\dots,R=\Vert\underline{a}_k-\underline{r}\Vert^2_\underline{r}=\large\sum_{j=1}^C\dfrac{(\underline{a}_{k_j}-r_{j})^2}{r_j} \]
d2.row <- apply(row.profile, 1,
function(row.p, av.p){sum(((row.p - av.p)^2)/av.p)},
average.row.profile)
as.matrix(round(d2.row,3)) %>%
kable(
align = "rc",
col.names = c("Task", "Similarity"),
digits = 3,
caption = "Similarity between each row profile and the average row profile",
) %>%
kable_classic()| Task | Similarity |
|---|---|
| Laundry | 1.329 |
| Main_meal | 1.034 |
| Dinner | 0.618 |
| Breakfeast | 0.512 |
| Tidying | 0.353 |
| Dishes | 0.302 |
| Shopping | 0.218 |
| Official | 0.968 |
| Driving | 1.274 |
| Finances | 0.456 |
| Insurance | 0.727 |
| Repairs | 3.307 |
| Holidays | 2.140 |
Distance (or similarity) between each col profile and the average col profile
This metrics is useful to compare how similar to the average col profile is any col profile.
\[ d^2_{l},\;l=1,\dots,C=\Vert\underline{b}_l-\underline{c}\Vert^2_\underline{c}=\large\sum_{i=1}^R\dfrac{(\underline{b}_{l_i}-c_i)^2}{c_i} \]
d2.col <- apply(col.profile, 2,
function(col.p, av.p){sum(((col.p - av.p)^2)/av.p)},
average.col.profile)
as.matrix(round(d2.col,3)) %>%
kable(
align = "rc",
col.names = c("Couple", "Similarity"),
digits = 3,
caption = "Similarity between each col profile and the average col profile",
) %>%
kable_classic()| Couple | Similarity |
|---|---|
| Wife | 0.875 |
| Alternating | 0.809 |
| Husband | 1.746 |
| Jointly | 1.078 |
Distance matrix
The similarity can be computed between each row (col) profile and the other row (col) profiles in the contingency table, using, for example, the function dist-matrix() (here).
# data: a data frame or matrix
# average.profile: average profile
dist.matrix <- function(data, average.profile) {
mat <- as.matrix(t(data))
n <- ncol(mat)
dist.mat <- matrix(NA, n, n)
diag(dist.mat) <- 0
for (i in 1:(n - 1)) {
for (j in (i + 1):n) {
d2 <- sum(((mat[, i] - mat[, j])^2) / average.profile)
dist.mat[i, j] <- dist.mat[j, i] <- d2
}
}
colnames(dist.mat) <- rownames(dist.mat) <- colnames(mat)
dist.mat
}The result is a distance matrix (a kind of correlation or dissimilarity matrix), either orientated per rows or columns. The distance between row (col) profiles can be computed using the package corrplot for visualization.
Row distance matrix
# Distance matrix (row)
dist.mat <- dist.matrix(row.profile, average.row.profile)
dist.mat <- round(dist.mat, 2)
# Visualize the matrix (row)
corrplot(dist.mat, type = "upper", is.corr = FALSE, col = colorRampPalette(c("white", "steelblue"))(128))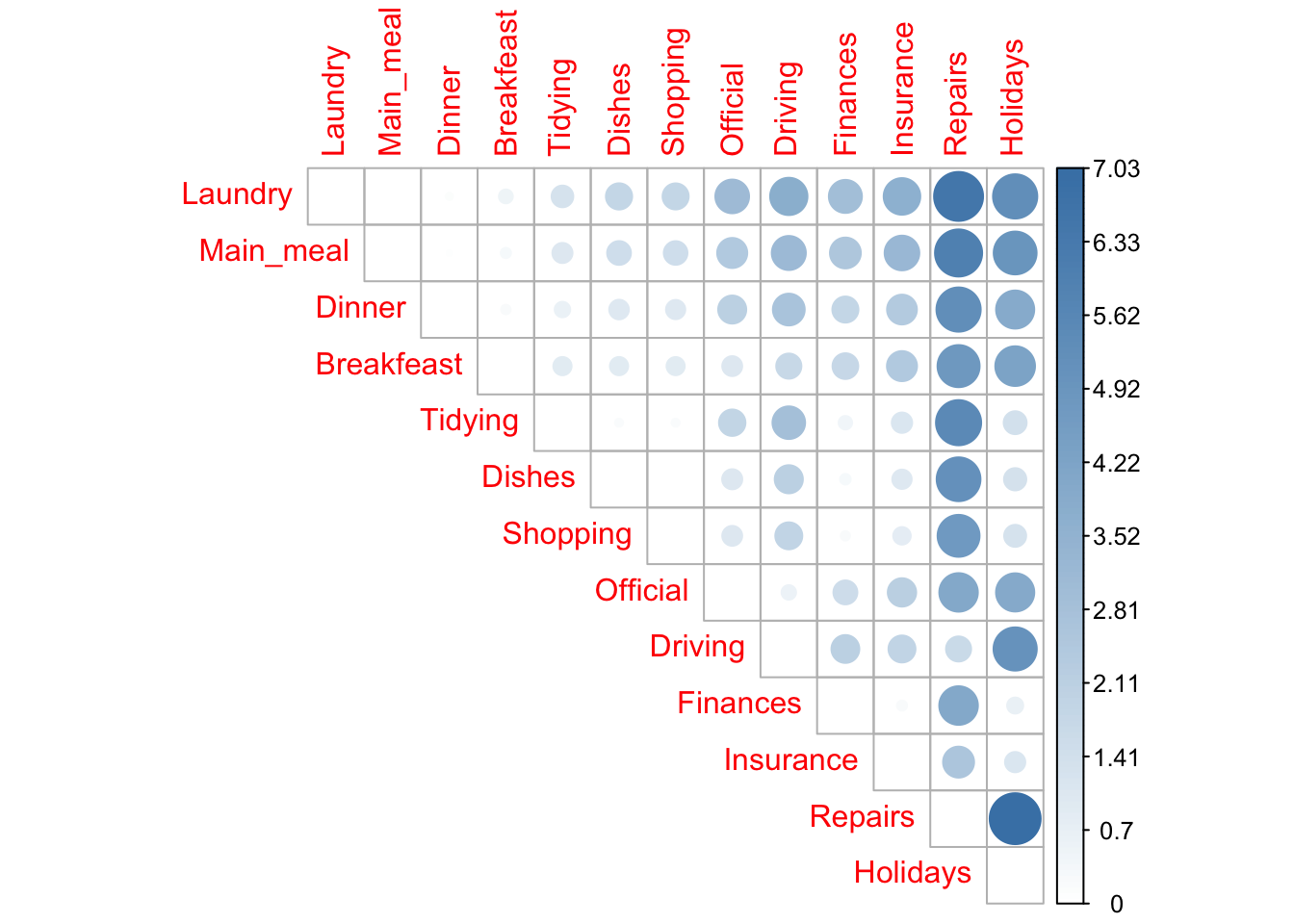
Col distance matrix
# Distance matrix (column)
dist.mat <- dist.matrix(t(col.profile), average.col.profile)
dist.mat <- round(dist.mat, 2)
# Visualize the matrix (column)
corrplot(dist.mat, type = "upper", is.corr = FALSE, col = colorRampPalette(c("white", "steelblue"))(128))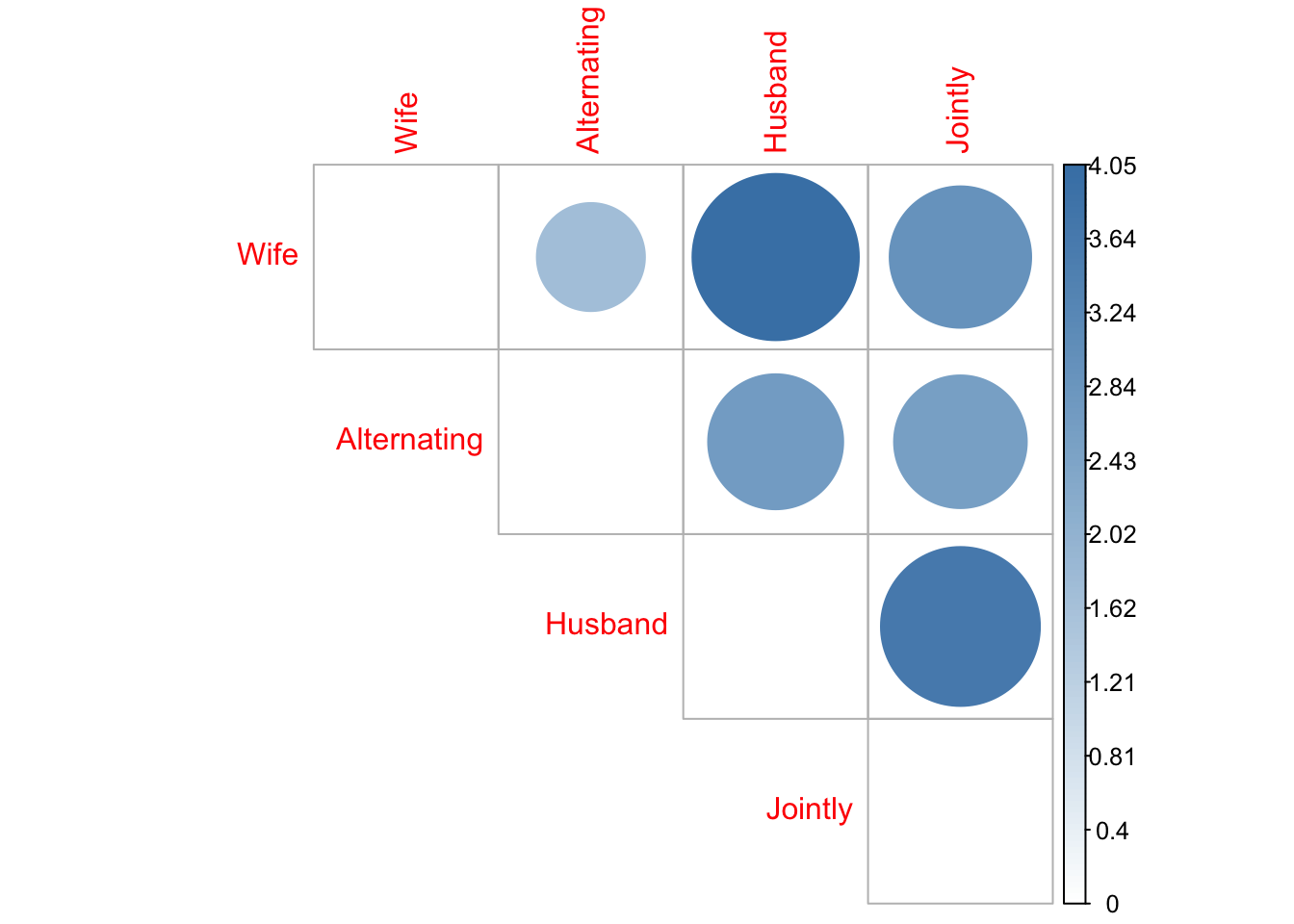
Row mass and inertia
The row mass can be defined as the total frequency of each row, obtained by dividing its row sum by the gran total. The row inertia is calculated as the row mass multiplied by the squared distance between the row and the average row profile. The inertia is a measure of the information contained in each row.
# Row mass
row.sum <- apply(housetasks, 1, sum)
grand.total <- sum(housetasks)
row.mass <- row.sum/grand.total
# Row inertia
row.inertia <- row.mass*d2.row
row.inertia %>%
kable(
align = "rc",
col.names = c("Task", "Inertia"),
digits = 3,
caption = "Row inertia of the house tasks contingency table",
) %>%
kable_classic()| Task | Inertia |
|---|---|
| Laundry | 0.134 |
| Main_meal | 0.091 |
| Dinner | 0.038 |
| Breakfeast | 0.041 |
| Tidying | 0.025 |
| Dishes | 0.020 |
| Shopping | 0.015 |
| Official | 0.053 |
| Driving | 0.102 |
| Finances | 0.030 |
| Insurance | 0.058 |
| Repairs | 0.313 |
| Holidays | 0.196 |
Column mass and inertia
The column mass can be defined as the total frequency of each column, obtained by dividing its col sum by the gran total. The column inertia is calculated as the column mass multiplied by the squared distance between the column and the average col profile. The inertia is a measure of the information contained in each column.
# Column mass
col.sum <- apply(housetasks, 2, sum)
grand.total <- sum(housetasks)
col.mass <- col.sum/grand.total
# Column inertia
col.inertia <- col.mass*d2.col
col.inertia %>%
kable(
align = "rc",
col.names = c("Couple", "Inertia"),
digits = 3,
caption = "Column inertia of the house tasks contingency table",
) %>%
kable_classic()| Couple | Inertia |
|---|---|
| Wife | 0.301 |
| Alternating | 0.118 |
| Husband | 0.381 |
| Jointly | 0.315 |
Total inertia
The total inertia is the total information contained in the contingency table.
# Total inertia
inertia_total_row <- sum(row.inertia)
inertia_total_col <- sum(col.inertia)The total inertia is computed as the sum of row inertias (or equivalently, as the sum of column inertias), in the present case we get the value 1.115.
# Row mass
row.sum <- apply(housetasks, 1, sum)
grand.total <- sum(housetasks)
row.mass <- row.sum/grand.total
# Row inertia
row.inertia <- row.mass*d2.row
# Total inertia
inertia_total_row <- sum(row.inertia)
# Column mass
col.sum <- apply(housetasks, 2, sum)
col.mass <- col.sum/grand.total
# Column inertia
col.inertia <- col.mass*d2.col
# Total inertia
inertia_total_col <- sum(col.inertia)The result for rows can be summarized in terms of the squared distance between row profiles and the average row profile (i.e., d2.row), the row mass (i.e., row mass), and the row inertia (i.e., row.inertia). Similarly, the results for columns can be summarized using d2.col, col.mass and col.inertia.
row <- cbind.data.frame(d2 = d2.row, mass = row.mass, inertia = row.inertia)
col <- cbind.data.frame(d2 = d2.col, mass = col.mass, inertia = col.inertia)
row %>%
kable(
align = "rrrr",
col.names = c("Task", "Squared distance", "Mass", "Inertia"),
digits = 3,
caption = "Summary statistics for the rows of the contingency table",
) %>%
kable_classic()| Task | Squared distance | Mass | Inertia |
|---|---|---|---|
| Laundry | 1.329 | 0.101 | 0.134 |
| Main_meal | 1.034 | 0.088 | 0.091 |
| Dinner | 0.618 | 0.062 | 0.038 |
| Breakfeast | 0.512 | 0.080 | 0.041 |
| Tidying | 0.353 | 0.070 | 0.025 |
| Dishes | 0.302 | 0.065 | 0.020 |
| Shopping | 0.218 | 0.069 | 0.015 |
| Official | 0.968 | 0.055 | 0.053 |
| Driving | 1.274 | 0.080 | 0.102 |
| Finances | 0.456 | 0.065 | 0.030 |
| Insurance | 0.727 | 0.080 | 0.058 |
| Repairs | 3.307 | 0.095 | 0.313 |
| Holidays | 2.140 | 0.092 | 0.196 |
col %>%
kable(
align = "rrrr",
col.names = c("couple", "squared distance", "mass", "inertia"),
digits = 3,
caption = "Summary statistics for the columns of the contingency table",
) %>%
kable_classic()| couple | squared distance | mass | inertia |
|---|---|---|---|
| Wife | 0.875 | 0.344 | 0.301 |
| Alternating | 0.809 | 0.146 | 0.118 |
| Husband | 1.746 | 0.218 | 0.381 |
| Jointly | 1.078 | 0.292 | 0.315 |
The chi-square statistic (\(\chi^2\)) is an overall measure of the difference between the frequencies observed in a contingency table and the expected frequencies calculated under the assumption of homogeneity of row profiles (or column profiles). Geometrically, the inertia measures how far away row profiles (or column profiles) are from their average profiles. The average profile can be thought of as the representative of the hypothesis of homogeneity (i.e., equality) of profiles. The distances between profiles are measured using the distance of the chi-square (distance \(\chi^2\)). This distance is similar in its formulation to the Euclidean distance between points in a physical space, except that any quadratic difference between coordinates is divided by the corresponding element of the mean profile.
It can be shown that the total inertia \(\Phi\) of a contingency table is the statistic (\(\chi^2\)) divided by the grand total \(n\):
\[ \Phi=\dfrac{\chi^2}{n}=\sum_{i}^Rc_i\Vert\underline{a}_i-\underline{r}\Vert^2_{\underline{r}}=\sum_{j}^Cr_j\Vert\underline{b}_j-\underline{c}\Vert^2_{\underline{c}} \]
The Chi-squared test can be used to examine whether rows and columns of a contingency table are statistically significantly associated:
For each cell of the table, we have to calculate the expected value under H0. For a given cell \((i,j)\), the expected value is calculated by taking the product of the \(i\)-th element of the row margin (sum of the elements in the \(i\)-th row of the contingency table) and the \(j\)-th element of the col margin (sum of the elements in the \(j\)-th column of the contingency table), divided by the gran total.
Suppose that the population is divided into \(R\) groups and each group (or the entire population) is divided into \(C\) categories. We would like to test whether the distribution of categories in each group is the same (homogeneity test). If observations \(X_1,\dots,X_n\) are sampled independently from the entire population then homogeneity over groups is the same as independence of groups and categories. If we have homogeneity:
\[ \text{Pr}(\text{Category}_j\vert\text{Group}_i)=\text{Pr}(\text{Category}_j) \]
then we have independence:
\[ \text{Pr}(\text{Category}_j,\text{Group}_i)=\text{Pr}(\text{Category}_j\vert\text{Group}_i)\text{Pr}(\text{Group}_i)=\text{Pr}(\text{Category}_j)\text{Pr}(\text{Group}_i) \]
It is also possible to move the other way around (i.e., start from independence to obtain homogeneity). In other words, to test homogeneity, we can use the test of independence. The computation of the expected cell counts under the null hypothesis H0 (the row and the column variables of the contingency table are independent) is done according to the scheme of Figure 1.
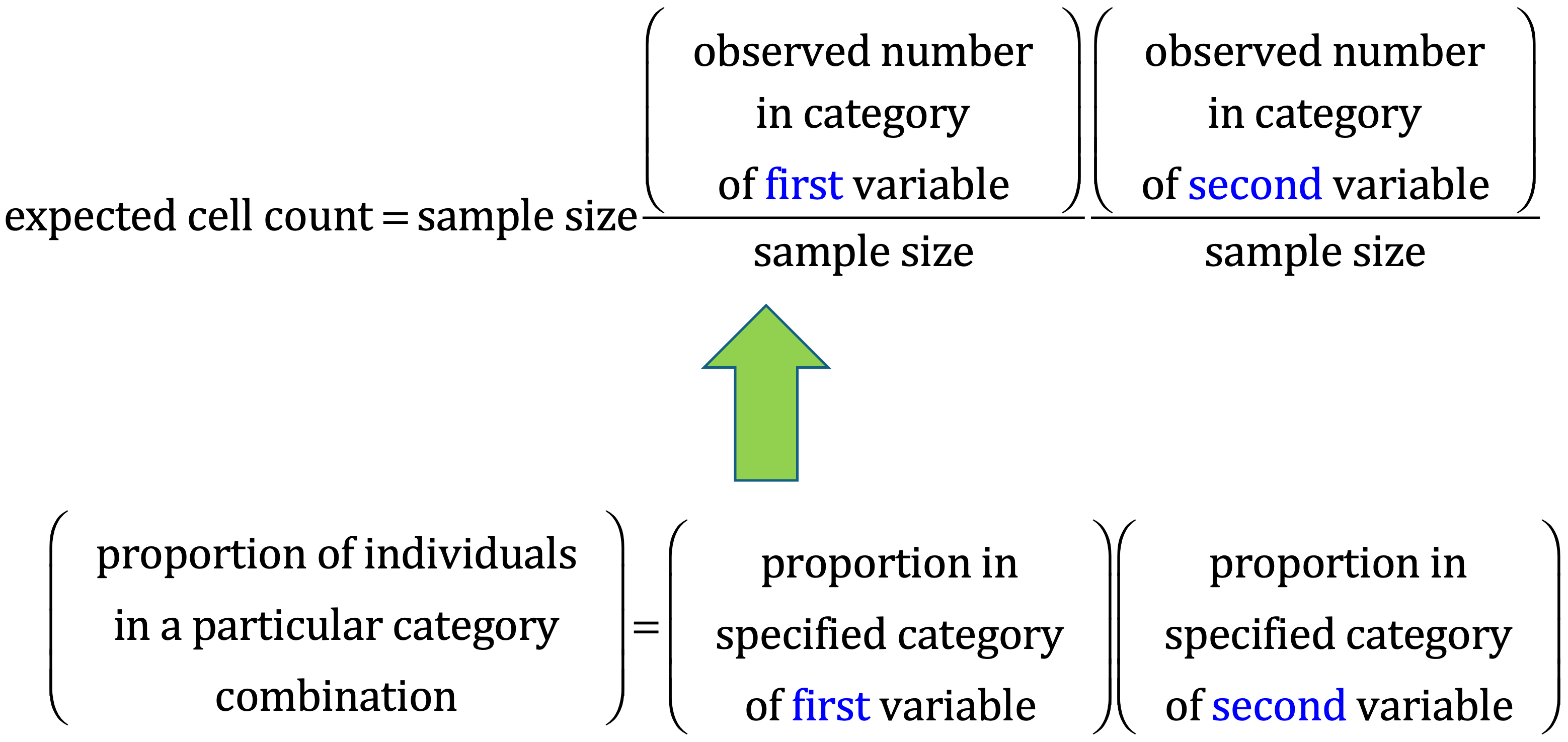
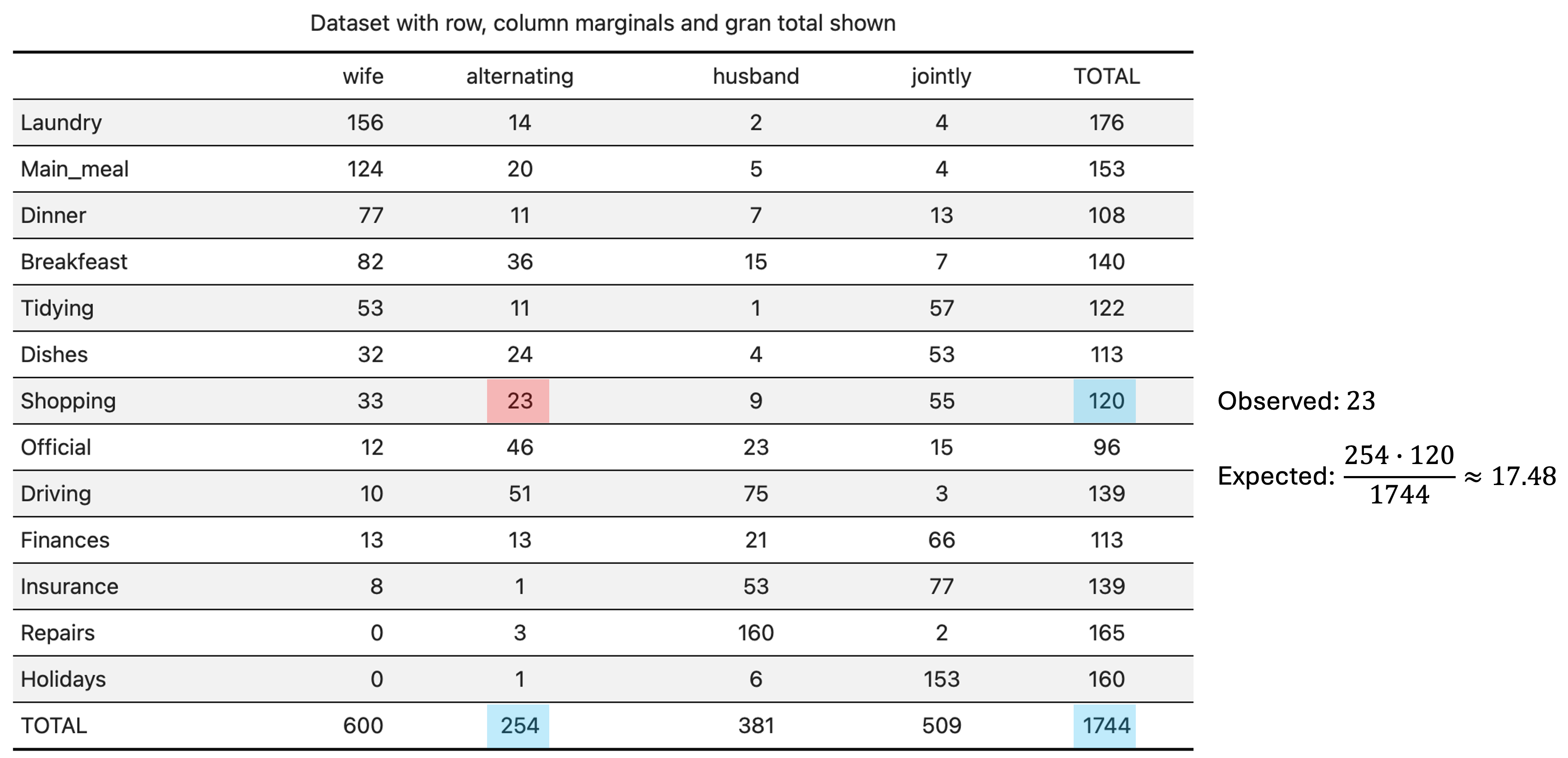
For example, in the case of the house tasks contingency table, the scheme of computation for the cell “Shopping”-“Alternating” is shown in Figure 2.
# Table of expected counts
E = (row.sum %*% t(col.sum))/n
row.names(E) <- row.names(housetasks)
E %>%
kable(
align = "rrrr",
col.names = c("Wife", "Alternating", "Husband", "Jointly"),
digits = 2,
caption = "Table of expected counts",
) %>%
kable_classic()| Wife | Alternating | Husband | Jointly | |
|---|---|---|---|---|
| Laundry | 60.55 | 25.63 | 38.45 | 51.37 |
| Main_meal | 52.64 | 22.28 | 33.42 | 44.65 |
| Dinner | 37.16 | 15.73 | 23.59 | 31.52 |
| Breakfeast | 48.17 | 20.39 | 30.58 | 40.86 |
| Tidying | 41.97 | 17.77 | 26.65 | 35.61 |
| Dishes | 38.88 | 16.46 | 24.69 | 32.98 |
| Shopping | 41.28 | 17.48 | 26.22 | 35.02 |
| Official | 33.03 | 13.98 | 20.97 | 28.02 |
| Driving | 47.82 | 20.24 | 30.37 | 40.57 |
| Finances | 38.88 | 16.46 | 24.69 | 32.98 |
| Insurance | 47.82 | 20.24 | 30.37 | 40.57 |
| Repairs | 56.77 | 24.03 | 36.05 | 48.16 |
| Holidays | 55.05 | 23.30 | 34.95 | 46.70 |
The calculated Chi-square statistic \(\chi^2\) is compared to the critical value (obtained from statistical tables) with \(df=(R-1)(C-1)\) degrees of freedom and \(p=0.05\). Recall that \(R, C\) are the number of rows and columns in the contingency table, respectively. If the calculated Chi-square statistic is greater than the critical value, then we must conclude that the row and the column variables are not independent of each other. This implies that they are significantly associated. The function chisq.test() can be used to implement the test.
The result of chisq.test() function is a list containing the following components:
It is worth noting that the total inertia is equal to the total Chi-square score divided by the grand total. The square root of the total inertia is called trace and may be interpreted as a correlation coefficient. Any value of the trace > 0.2 indicates a significant dependency between rows and columns. In the present example 1.056.
If we want to know the most contributing cells to the total Chi-square score, we just have to calculate the Chi-square statistic for each cell:
\[ r_{ij} = \dfrac{o_{ij}-e_{ij}}{\sqrt{e_{ij}}},\,i=1,\dots,R;\,j=1,\dots,C \]
The above formula returns the so-called Pearson residuals (\(r\)) for each cell (or standardized residuals). Cells with the highest absolute standardized residuals contribute the most to the total Chi-square score. Pearson residuals can be easily extracted from the output of the function chisq.test().
chisq <- chisq.test(housetasks)
chisq
Pearson's Chi-squared test
data: housetasks
X-squared = 1944.5, df = 36, p-value < 2.2e-16# Observed counts
chisq$observed Wife Alternating Husband Jointly
Laundry 156 14 2 4
Main_meal 124 20 5 4
Dinner 77 11 7 13
Breakfeast 82 36 15 7
Tidying 53 11 1 57
Dishes 32 24 4 53
Shopping 33 23 9 55
Official 12 46 23 15
Driving 10 51 75 3
Finances 13 13 21 66
Insurance 8 1 53 77
Repairs 0 3 160 2
Holidays 0 1 6 153# Expected counts
round(chisq$expected, 2) Wife Alternating Husband Jointly
Laundry 60.55 25.63 38.45 51.37
Main_meal 52.64 22.28 33.42 44.65
Dinner 37.16 15.73 23.59 31.52
Breakfeast 48.17 20.39 30.58 40.86
Tidying 41.97 17.77 26.65 35.61
Dishes 38.88 16.46 24.69 32.98
Shopping 41.28 17.48 26.22 35.02
Official 33.03 13.98 20.97 28.02
Driving 47.82 20.24 30.37 40.57
Finances 38.88 16.46 24.69 32.98
Insurance 47.82 20.24 30.37 40.57
Repairs 56.77 24.03 36.05 48.16
Holidays 55.05 23.30 34.95 46.70# Pearson's residuals
e <- chisq$residuals
# Contribution in percentage of each cell (%)
contrib <- 100*chisq$residuals^2/chisq$statisticThe sign of the standardized residuals is also very important to interpret the association between rows and columns. Positive values in cells specify an attraction (positive association) between the corresponding row and column variables, such as, for instance, between the column “Wife” and the row “Laundry”. There is a strong positive association between the column “Husband” and the row “Repairs”. A negative residual implies a repulsion (negative association) between the corresponding row and column variables. For example the column “Wife” is negatively associated (i.e., “not associated”) with the row “Repairs”. There is a repulsion between the column “Husband” and the rows “Laundry” and “Main_meal”.
The contribution (in %) of a given cell to the total Chi-square score can be calculated as follows:
\[ \text{contrib}\,(\%)=100\,\dfrac{r^2}{\chi^2} \]
The relative contribution of each cell to the total Chi-square score give some indication of the nature of the dependency between rows and columns of the contingency table. It can be seen that:
e %>%
kable(
align = "rrrr",
col.names = c("Wife", "Alternating", "Husband", "Jointly"),
digits = 2,
caption = "Pearson's residuals",
) %>%
kable_classic()| Wife | Alternating | Husband | Jointly | |
|---|---|---|---|---|
| Laundry | 12.27 | -2.30 | -5.88 | -6.61 |
| Main_meal | 9.84 | -0.48 | -4.92 | -6.08 |
| Dinner | 6.54 | -1.19 | -3.42 | -3.30 |
| Breakfeast | 4.88 | 3.46 | -2.82 | -5.30 |
| Tidying | 1.70 | -1.61 | -4.97 | 3.59 |
| Dishes | -1.10 | 1.86 | -4.16 | 3.49 |
| Shopping | -1.29 | 1.32 | -3.36 | 3.38 |
| Official | -3.66 | 8.56 | 0.44 | -2.46 |
| Driving | -5.47 | 6.84 | 8.10 | -5.90 |
| Finances | -4.15 | -0.85 | -0.74 | 5.75 |
| Insurance | -5.76 | -4.28 | 4.11 | 5.72 |
| Repairs | -7.53 | -4.29 | 20.65 | -6.65 |
| Holidays | -7.42 | -4.62 | -4.90 | 15.56 |
contrib %>%
kable(
align = "rrrr",
col.names = c("Wife", "Alternating", "Husband", "Jointly"),
digits = 2,
caption = "Percentage contribution to the total Chi square",
) %>%
kable_classic()| Wife | Alternating | Husband | Jointly | |
|---|---|---|---|---|
| Laundry | 7.74 | 0.27 | 1.78 | 2.25 |
| Main_meal | 4.98 | 0.01 | 1.24 | 1.90 |
| Dinner | 2.20 | 0.07 | 0.60 | 0.56 |
| Breakfeast | 1.22 | 0.61 | 0.41 | 1.44 |
| Tidying | 0.15 | 0.13 | 1.27 | 0.66 |
| Dishes | 0.06 | 0.18 | 0.89 | 0.63 |
| Shopping | 0.09 | 0.09 | 0.58 | 0.59 |
| Official | 0.69 | 3.77 | 0.01 | 0.31 |
| Driving | 1.54 | 2.40 | 3.37 | 1.79 |
| Finances | 0.89 | 0.04 | 0.03 | 1.70 |
| Insurance | 1.71 | 0.94 | 0.87 | 1.68 |
| Repairs | 2.92 | 0.95 | 21.92 | 2.28 |
| Holidays | 2.83 | 1.10 | 1.23 | 12.45 |
SCA is just the singular value decomposition of the standardized residuals. How to perform this analysis using the R programming software will be explained in a future post (here), together with some discussion of the implications that the results of the analysis may have.